앞의 글을 읽으시면 이해에 도움이 됩니다.
[컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V의 기본적인 구현)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.09.24 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블리어) [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블
hi-guten-tag.tistory.com
2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelining
[컴퓨터 구조] Pipelining
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.01 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V의 기본적인 구현) [컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V
hi-guten-tag.tistory.com
1. Pipelined Datapath
이제부터는 본격적으로 실제 구현된 Datapath를 살펴봅니다.
Pipelining 글에서는 cpu가 총 다섯 개의 stage로 나누어서 연산을 진행한다고 설명드렸습니다.
이를 Datapath위에 그림을 나타내면, 아래와 같습니다.
기존의 Simple Version과 동일합니다.
(Simple Version은 나중에 시간이 나면 정리할 예정)
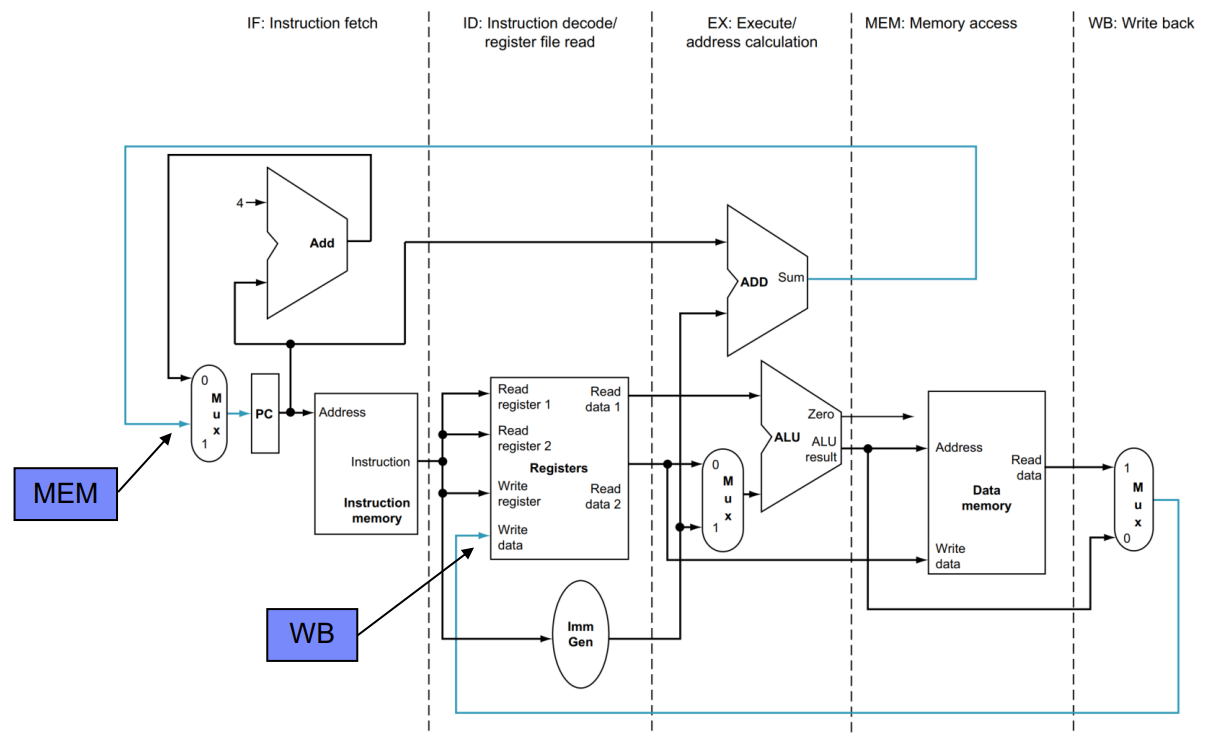
우선 control이 생략되었고, WB, MEM이 원래 알던 위치보다 앞 단계에서 발생하고 있습니다.
사실상 MEM 단계에서 PC update가 일어나게 되는데, 이를 조금 더 보기 편하게 하기 위해서 이렇게 표시했습니다.
또한 WB도 마지막 단계에서 일어나지만 실제 path를 따라가면 해당 위치에서 WB가 발생하기 때문에 표시했습니다.
(딱히 중요한 내용은 아닙니다.)
2. Pipeline Register
Pipeline에서는 앞선 stage의 정보를 저장하는 특별한 Register가 필요합니다.
이를 Pipeline Register라고 합니다.
ID stage에서 사용하는 명령어나 레지스터 번호 등은 IF stage에서는 더 이상 없습니다.
왜냐면 ID stage에서 어떤 명령어를 실행하고 있으면, IF stage는 pipeline 기법에 의해 다른 명령어를 반입하고 있기 때문입니다.
따라서 중간 중간 연산의 결과, 명령어 등을 저장하는 Pipeline Register가 필요합니다.
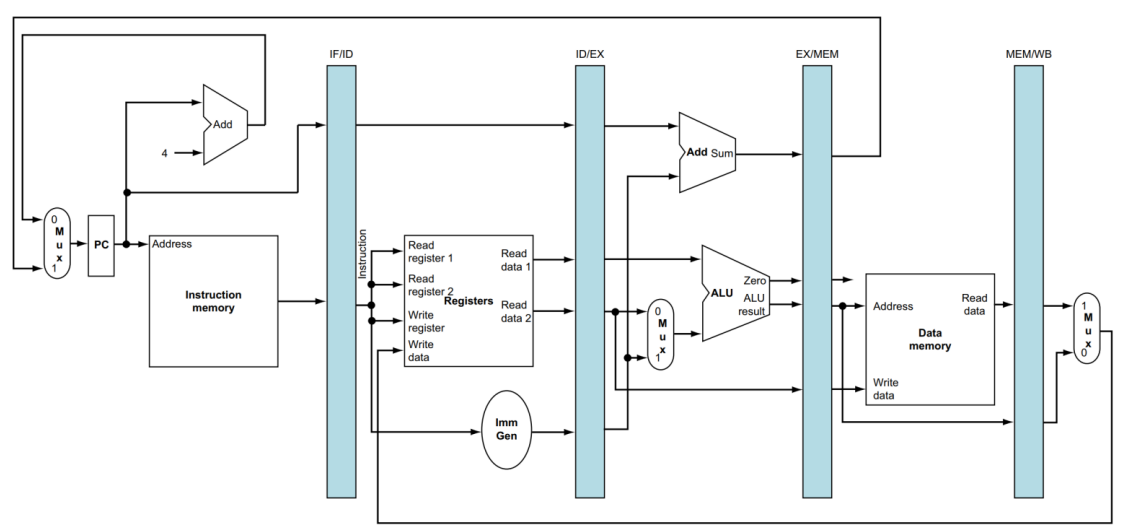
Register는 모든 데이터를 저장할 수 있을 만큼 충분히 커야 합니다.
IF와 ID stage 사이에 있는 Register를 IF/ID Register라고 합니다.
다른 Register도 이름이 앞선 stage와 다음 stage로 표현됩니다.
만약 32-bit architecture라면, 해당 Register의 크기는 32-bit 명령어 + 32-bit PC address를 더하여 64-bit 크기를 가져야 합니다.
ID/EX라면 32 + 32 + 32 + 32 = 128-bit의 크기를 가져야 합니다.
이제부터 각 단계별로 살펴봅시다.
먼저 IF 단계입니다.
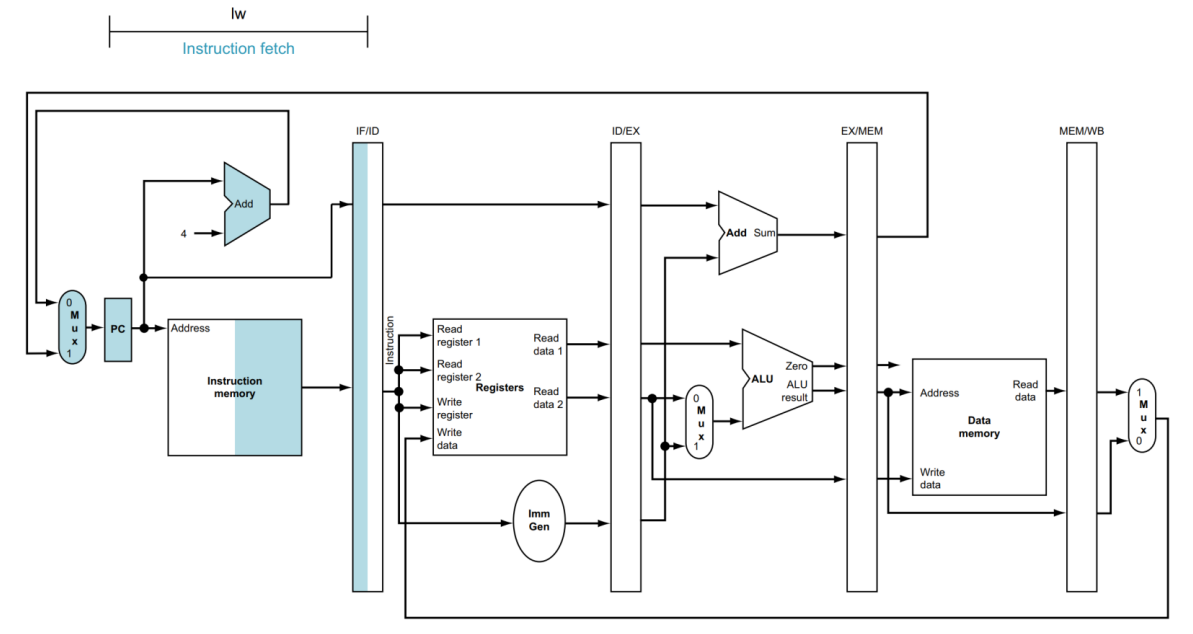
해당 단계에서는 PC 값을 기준으로 주소를 가지고 오며, 그와 동시에 PC에 4가 add 됩니다.
(지금은 branch 명령어는 고려하지 않습니다.)
그러고 나서 IF/ID Register에 명령어와 현재 PC address를 Write 합니다.
다음은 ID 단계입니다.
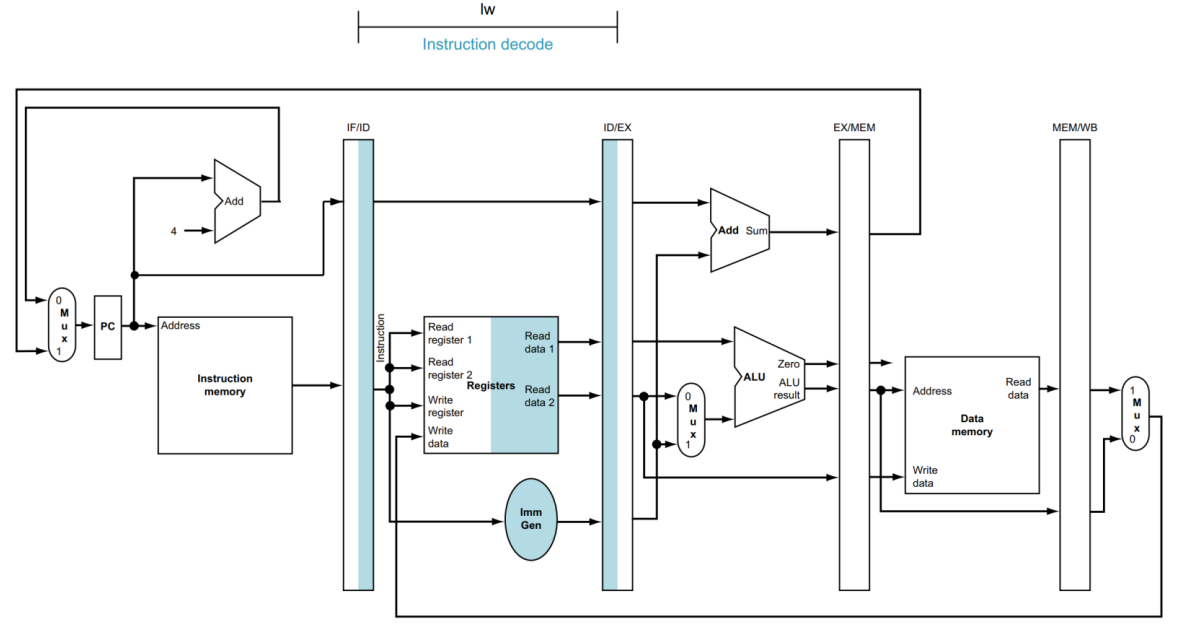
해당 단계에서는 IF/ID Register에 있는 명령어와 PC 값을 읽습니다.
(실제 사용은 명령어만 사용함)
읽어 들인 명령어를 바탕으로 Register Read를 하고, Imm Gen에서 Immediate 값을 추출합니다.
그러고 나서 ID/EX에 레지스터의 정보와 PC address, 복원된 Immediate 정보를 Write 합니다.
(정리는 안 했지만, Imm Gen은 명령어에서 Imm 값을 읽은 후, sign-extension 방식으로 imm 값을 32-bit 확장합니다.
I-type 같은 경우에는 12-bit가 imm으로 할당되어 있지만, 해당 Imm Gen을 통과하면 sign-extended 32-bit가 됩니다.)
다음은 EX 단계입니다.
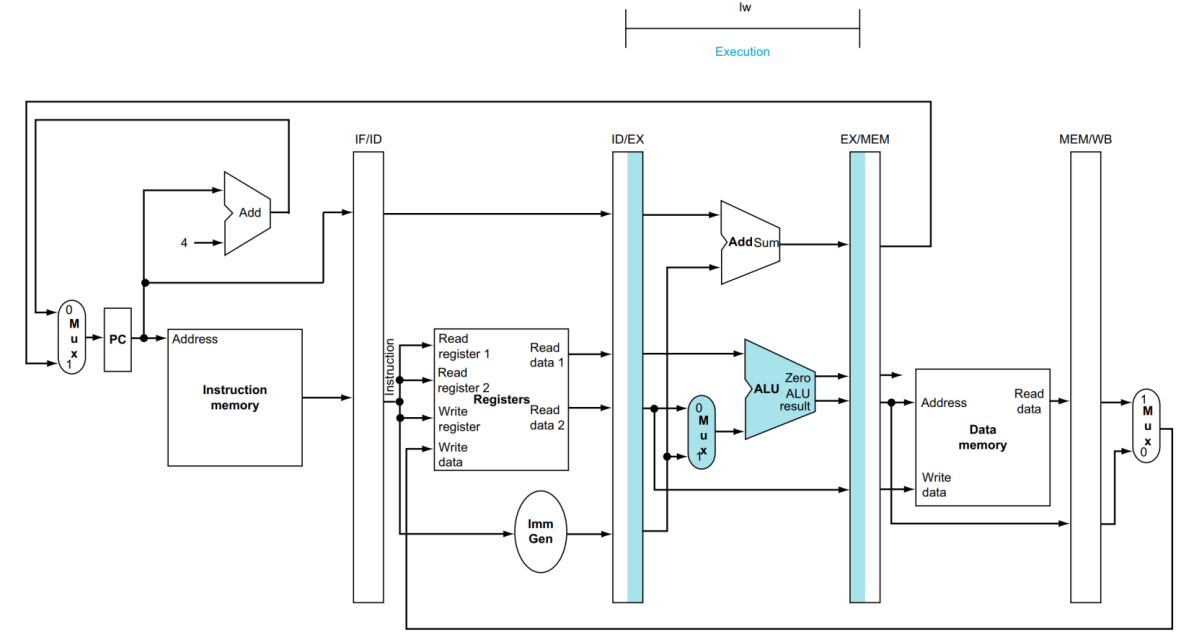
해당 단계에서는 연산을 수행합니다.
만약 주솟값이라면 덧셈을 진행하고, R-Type이라면 그에 맞는 명령을 수행합니다.
또한 branch 명령어라면 위에 있는 Add를 실행하여 PC address를 update 합니다.
마찬가지로 모든 실행이 끝나면 모든 정보를 EX/MEM에 Write 합니다.
만약에 명령어가 addi 라면 Register 1번 값과 Immediate 값만 덧셈을 수행합니다.
다만 이때 Register 2번의 값이 EX/MEM에 입력되는데, 멀티플렉서에서 무시되므로 신경 쓰지 않아도 됩니다.
다음은 MEM 단계입니다.
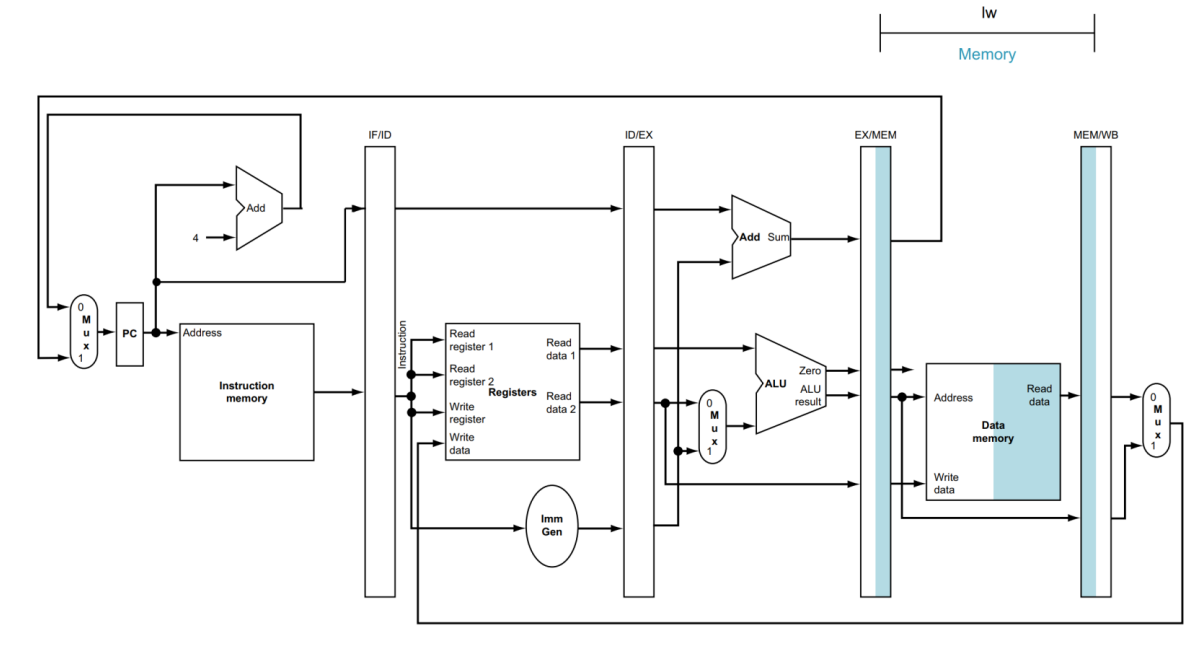
해당 단계에서는 계산된 address를 바탕으로 data memory에서 값을 읽습니다.
읽힌 data는 MEM/WB에 기록됩니다.
다음은 WB 단계입니다.
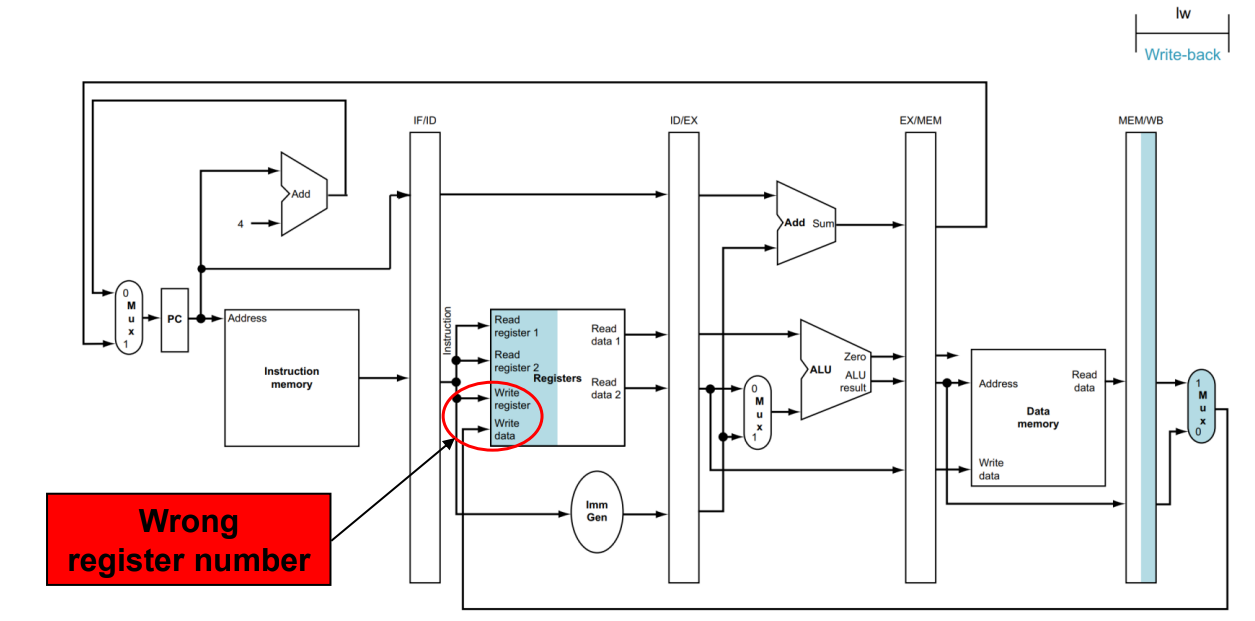
해당 단계에서는 값을 register에 입력하는 단계입니다.
하지만 여기서 문제점이 생기는데, 어느 Register에 입력해야 할지 정보를 잃은 상태입니다.
이유는 IF/ID Register은 다른 명령어가 이미 존재하는 상태입니다. (4번째 명령어가 먹은 상태)
따라서 나는 x1에 값을 입력하고 싶은데, 다른 명령어가 존재하기 때문에 x3에 입력을 하는 상태가 발생할 수 있습니다.
따라서 WB를 할 때, 어느 Register에 입력을 해야 하는지 같이 알려줘야 합니다.
그러므로 Destination Register의 번호는 ID/EX, EX/MEM, MEM/WB Register에서 보장되어야 합니다.
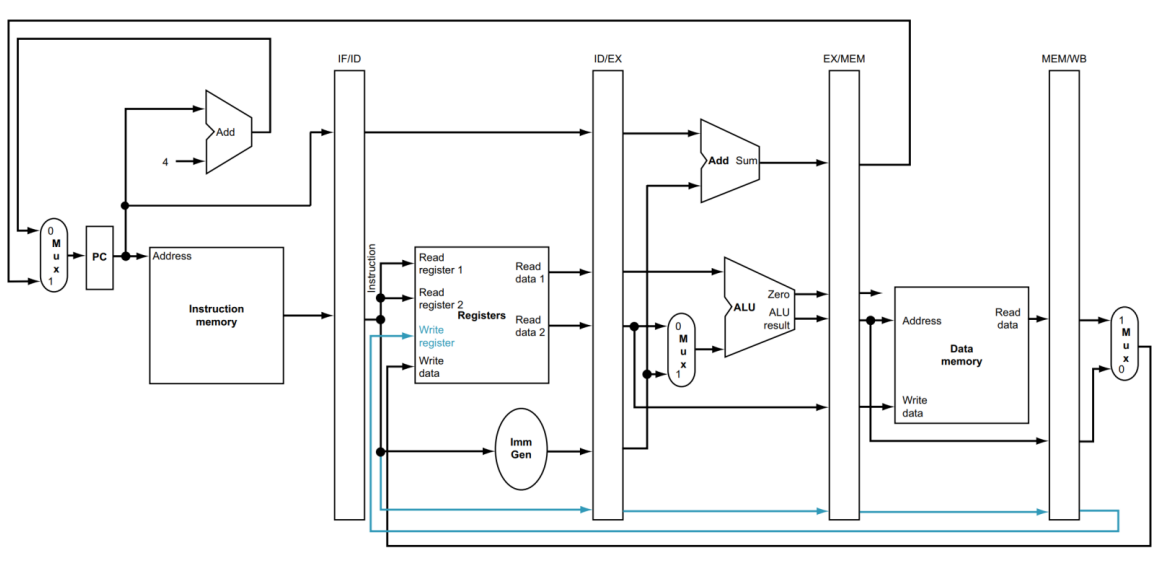
그렇기 때문에 Pipeline Register에서 rd를 위한 또 다른 path가 존재하며, rd 번호를 계속해서 들고 다니며,
최종적으로 WB에서 제대로 된 Register에 값을 입력합니다.
그렇다며 만약에 store 같은 명령어는 어떻게 될까요?
3. Write Back for Store Instruction
Store Insturction 같은 경우에는 사실 WB를 쓸 필요가 없습니다.
그렇다면 WB stage를 건너뛸 수는 없을까요?
아쉽게도 그럴 수는 없습니다.
Store는 WB stage가 필요 없지만, 그래도 진행은 합니다.
없앨 수가 없습니다. 다만 아무것도 하지 않습니다.
따라서 stage는 흘러갑니다.
그러므로 Store에 WB stage는 없다는 말은 틀린 말입니다.
존재는 하지만, 아무것도 하지 않습니다.
4. Single Clock Cycle Pipeline Diagram
어떤 한 Clock을 기준으로 CPU를 본다면 아래의 그림과 같습니다.
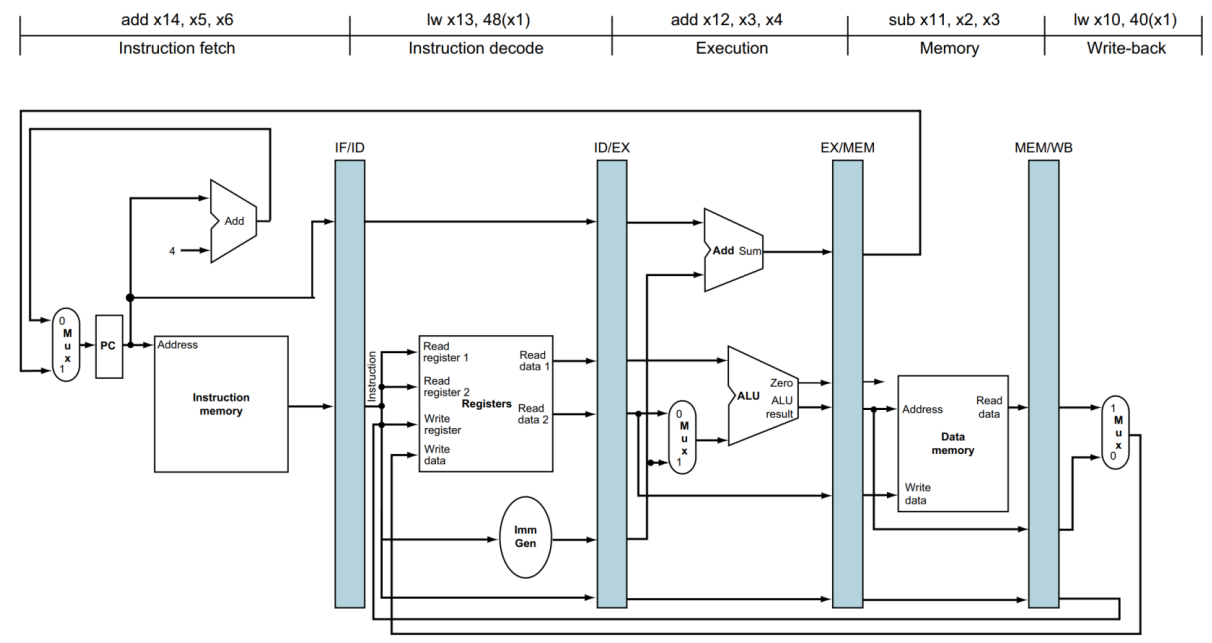
datapath에 각각의 instruction이 자리하고 있습니다.
따라서 여기에 추가적으로 Pipelined Control이 추가되어야 합니다.
이는 다음 글에서 쓰도록 하겠습니다.
2022.11.16 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelined Control
[컴퓨터 구조] Pipelined Control
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.16 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelined Datapath [컴퓨터 구조] Pipelined Datapath 앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.01 -
hi-guten-tag.tistory.com
감사합니다.
지적 환영합니다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Data Hazard in Pipelined Datapath (0) | 2022.11.16 |
|---|---|
| [컴퓨터 구조] Pipelined Control (0) | 2022.11.16 |
| [컴퓨터 구조] Control Hazard (9) | 2022.11.11 |
| [컴퓨터 구조] Data Hazard (2) | 2022.11.11 |
| [컴퓨터 구조] Structural Hazard (0) | 2022.11.10 |