앞의 글을 읽으시면 이해에 도움이 됩니다.
[컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V의 기본적인 구현)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.09.24 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블리어) [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블
hi-guten-tag.tistory.com
목차
1. Pipelining
2. Stage
3. Performance 비교
1. Pipelining
원래는 SIngle Version부터 봐야 하는데, 우선은 Pipeline Version을 먼저 보겠습니다.
파이프라인 버전은 여러 개의 명령어를 동시에 수행하는 기법입니다.
거의 표준이고, 흔하게 사용되는 기법입니다.
Non-Pipelined Version은 일련의 과정을 모두 수행하고, 다음 과정을 진행합니다.
말로 설명하면 어려우니 예시를 들어봅시다.
예를 들어 Non-Pipelined 기법을 사용하여 빨래를 한다면 아래의 그림과 같습니다.
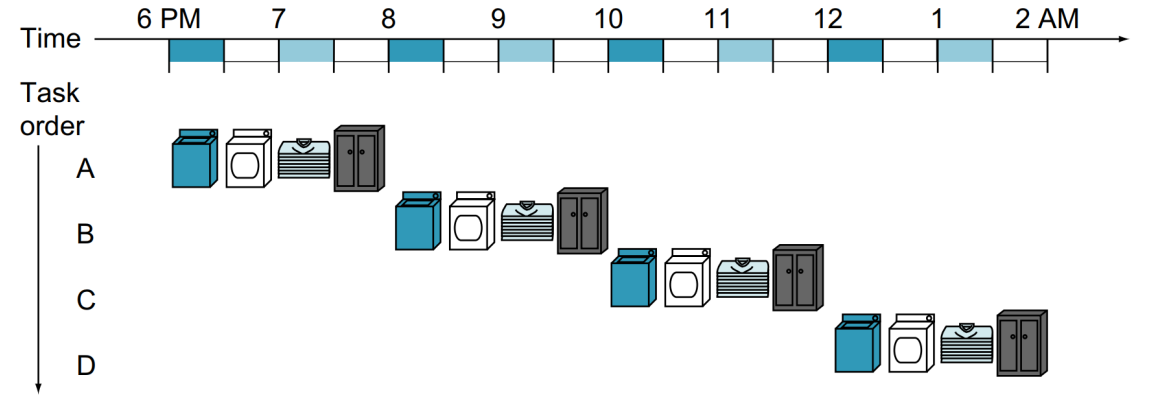
즉 일련의 과정을 모두 수행한 후, 다음 과정을 진행합니다.
만약 파이프라인 버전이라면 어떻게 될까요?
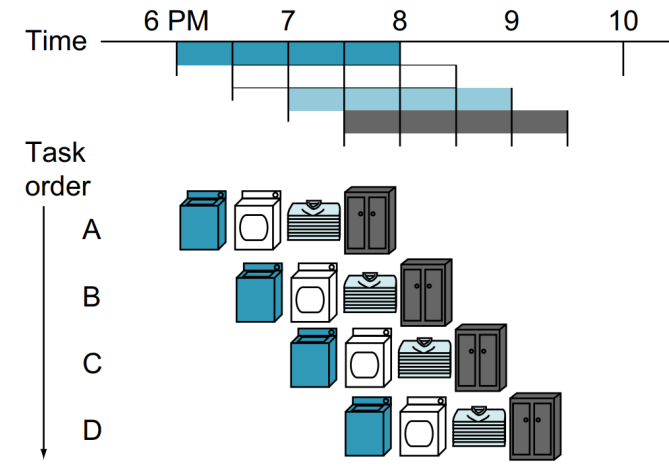
파이프라인 버전은 각 과정을 하나의 stage로 구분합니다.
따라서 하나의 시간축에 여러 개의 stage를 구성함으로써 throughput이 향상됩니다.
(다만 response time은 향상되지 않습니다.)
위의 non-pipeline은 모든 작업이 완료되는데 걸리는 시간이 16 time이고, 아래의 pipeline은 7 time만에 완료됩니다.
따라서 16/7 = 약 2.3배 정도 속도가 빨라졌습니다.
만약 이러한 빨래가 무한히 있다면 4n/(n+3) = 약 4배 정도 빨라질 겁니다.
2. Stage
앞에서 각 과정을 하나의 stage로 구분한다고 설명드렸습니다.
그렇다면 RISC-V의 하나의 명령어가 수행되기 위해서는 총 몇 개의 stage가 필요할까요?
총 5개의 stage가 필요합니다.
이때 stage는 다음과 같습니다.
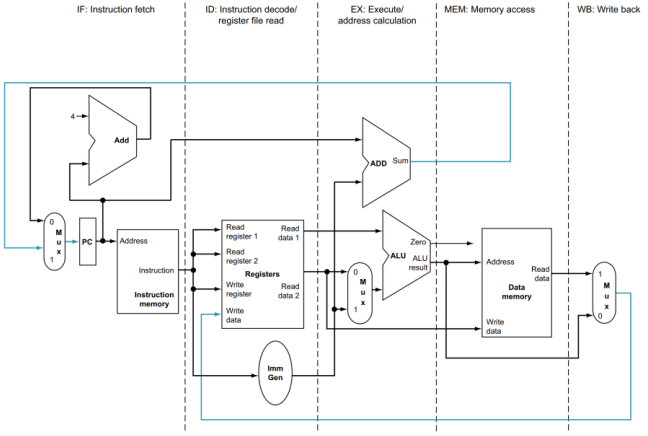

풀어서 설명해보겠습니다.
- IF : PC 값을 기준으로 메모리를 반입한다. 또한 PC를 update 한다.
- ID : 명령어를 해석하고, Register에서 값을 읽는다. 또한 Control 신호가 생성된다.
- EX : 작업을 실행한다. 혹은 주소를 계산한다.
- MEM : operand를 가지고, 메모리에 접근한다. (만약 add 같은 명령어라면 해당 stage는 아무것도 하지 않는다.)
- WB (write back) : register에 값을 입력한다. (위치는 ID stage지만, 사실상 실행 순서는 WB stage이다.)
그림의 글씨가 잘 안 보이지만, 뒤에 가면 각 단계마다 자세히 풀어서 설명하므로, 지금은 저런 stage로 구분되는구나 정도만 알아두셔도 무방할 것 같습니다.
아무튼 Non-Pipeline와 Pipeline version으로 나타낸다면 다음과 같습니다.


딱 봐도 시간이 줄어드는 게 느껴지시나요?
이처럼 CPU는 각 명령어를 총 5개의 stage로 나누어서, 하나의 stage에 하나의 작업을 합니다.
만약 3번째 time에서 작업을 한다면,
EX stage에서는 add를 수행할 것이고, ID stage에서는 x14, x15 register를 읽고, 아마 명령어를 해독하고 있을 겁니다.
또한 IF stage에서는 and x5, x6, x7 명령어를 반입하고 있을 겁니다.
3. Performance 비교
register file read or write : 100ps (10 Ghz)
other stage : 200ps라고 가정하겠습니다.
(1 ns = 1 Ghz, 1000 ps = 1 ns = 1 Ghz)
따라서 아래의 표는 명령어를 각 stage로 나누어, 시간을 계산한 표입니다.
(예시임)
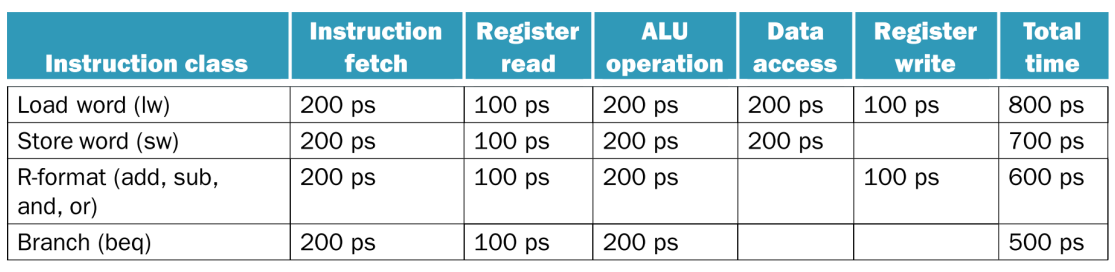
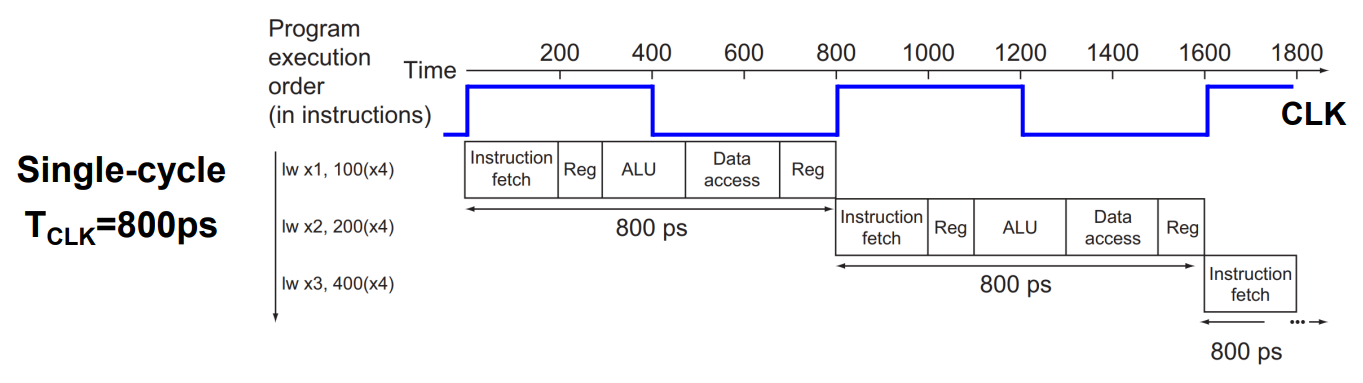
만약 Single Cycle이었다면, lw 명령어를 수행하는데 800ps가 걸릴 것입니다.
그러면 clock cycle도 800ps가 됩니다.
따라서 4번째 명령어를 시작하기까지 2.4 ns가 걸릴 것입니다.
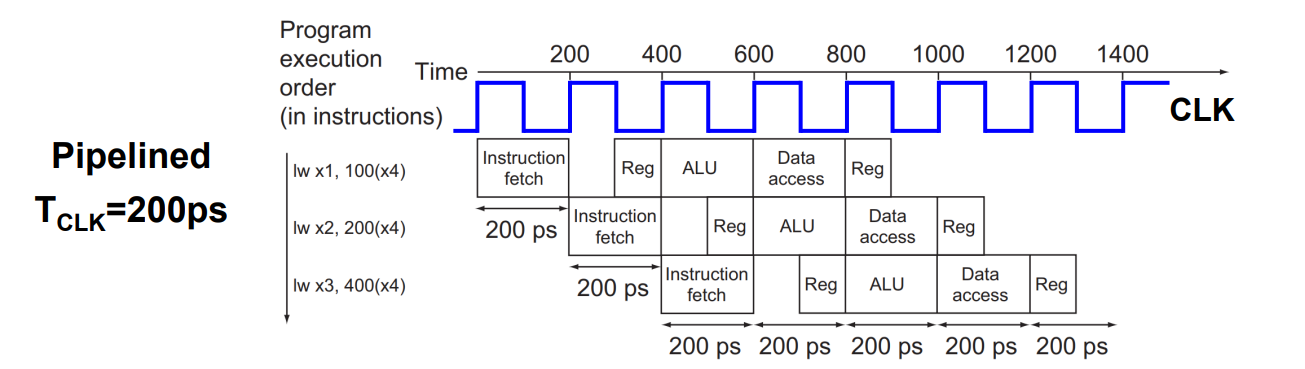
Pipeline에서는 하나의 stage가 하나의 Clock cycle을 가지고 있으므로, clock cycle은 가장 느린 작업에 맞춰야 합니다.
따라서 모든 stage는 200ps의 clock cycle을 가지게 되고, 4번째 명령어를 시작하기까지 600ps, 0.6ns만큼 걸립니다.
(물론 이때는 pipeline에 넣는 시간 또한 계산해야 하지만, 생략했습니다.)
만약 모든 stage가 같은 시간이라면, pipeline의 instruction clock cycle 공식은 다음과 같습니다.
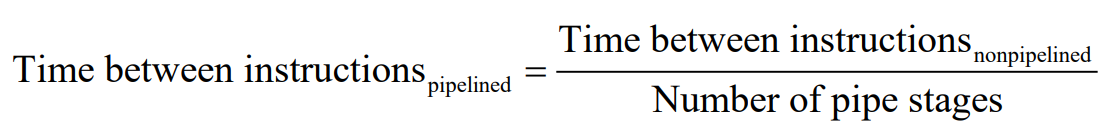
다만 stage가 모두 같은 시간이 아니라면 성능 향상은 저하됩니다.
200 ps가 5번 수행되면 1000 ps이고, 이를 pipeline으로 변경하여 무한히 수행한다면 5배의 성능 향상이 발생합니다.
하지만 위의 예시에서는 하나의 명령어가 800 ps이므로, pipeline으로 변경하여도 5배까지는 성능 향상이 발생하지 않습니다.
아무튼 Pipeline 기법은 각 명령어의 수행 시간을 줄이지 않고서도, 명령어 throughput을 향상합니다.
다음 글에서는 Pipeline을 사용했을 때 Hazard(위험 요소)에 대해서 알아보겠습니다.
2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Hazard
[컴퓨터 구조] Hazard
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelining [컴퓨터 구조] Pipelining 앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.01 - [Computer Scienc
hi-guten-tag.tistory.com
감사합니다.
지적 환영합니다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Structural Hazard (0) | 2022.11.10 |
|---|---|
| [컴퓨터 구조] Hazard (0) | 2022.11.10 |
| [컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V의 기본적인 구현) (2) | 2022.11.01 |
| [컴퓨터 구조] Measuring Performance (성능 측정) (0) | 2022.10.23 |
| [컴퓨터 구조] Division (0) | 2022.10.23 |