앞의 글을 읽으시면 이해에 도움이 됩니다.
2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Hazard
[컴퓨터 구조] Hazard
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelining [컴퓨터 구조] Pipelining 앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.01 - [Computer Scienc
hi-guten-tag.tistory.com
목차
1. Control Hazard
2. 해결법
3. Prediction
4. Dynamic Branch Prediction
1. Control Hazard
마지막 Hazard는 Control Hazard입니다.
Control Hazard는 conditional branch를 통해 PC 값을 바꿀 때, 이미 pipeline에 들어와 있는 명령어가 flush 되는 현상입니다.
즉 pipeline에 이미 반입된 다음 명령어들을 버려야 한다는 뜻입니다.
기본적으로 IF는 다음 명령어를 반입하고, branch는 MEM 단계에서 결정되어서 PC를 바꾸기 때문에,
최소 3 cycle bubble이 발생합니다.
pipeline은 항상 올바른 instruction을 반입할 수 없기 때문입니다.
conditional branch는 어떻게 해결할 수 있을까요?
2. 해결법
branch가 될지, 안 될지 미리 test하는 register를 추가로 사용해봅시다.
그러면 이 명령어가 branch이다 라는 조건과 Reg의 두 개의 값이 같다 라는 조건이 맞으면 되므로,
ID 단계에서 register를 추가로 사용하여 문제를 해결합니다.
아래에 그림을 그리면 다음과 같습니다.
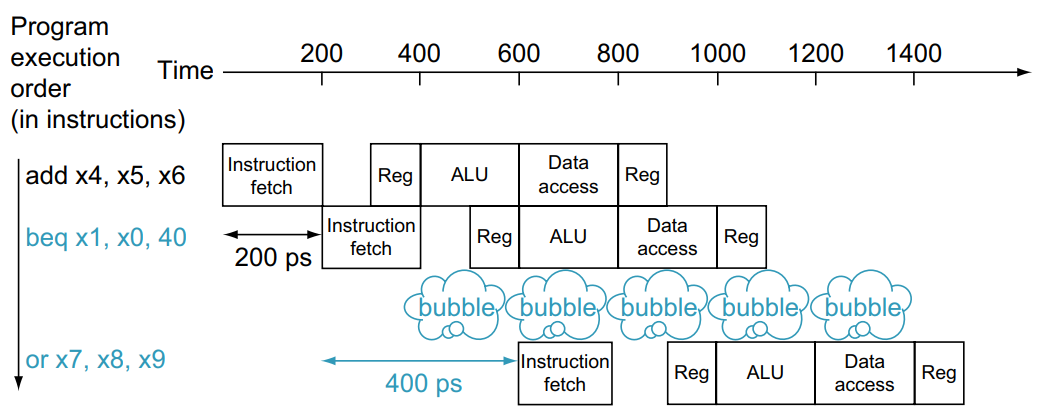
이처럼 MEM 단계에서 branch가 결정되던 기존의 datapath와는 달리 ID 단계에서 결정이 일어나서 1 cycle만 손해를 봅니다.
beq가 False라면 그냥 실행하지만, beq가 True 라면 branch를 다시 계산해서 멀리 있는 명령어를 재반입합니다.
하지만 명령어가 길다면 어떻게 될까요?
예를 들어 pipeline이 20 cycle이고, 중간에 branch를 한다는 것을 알아낸다 하더라도 10 cycle은 손해 봅니다.
그리고 재반입하여 수행합니다.
register를 추가한다 하더라도, stall로 인해 발생하는 페널티는 너무나 큰 것 같습니다.
그렇기 때문에 CPU는 Prediction을 합니다.
예측을 통하여 conditional branch가 taken 될지, 아니면 untaken 될 지 예측합니다.
기본적인 default 값은 untaken 될 것이라 예측합니다.
만약 prediction이 틀린다면 pipeline stall이 발생하게 됩니다.

3. Prediction
예측은 Static Branch Prediction과 Dynamic Branch Prediction으로 나뉩니다.
Static은 branch의 일반적인 행동을 기반으로 예측합니다.
loop 같은 경우에는 항상 branch가 taken 된다고 가정합니다.
만약 100번 loop 한다고 가정하면, 99번은 맞추고 1번은 틀리게 됩니다.
다만 Static의 경우에는 backward branch만 가능하고, forward branch는 불가능합니다.
Dynamic은 각각의 conditional branch의 과거를 기반으로 예측을 수행합니다.
하드웨어에서 각 branch마다 과거를 기억하고 있어서, 해당 branch의 트렌드로 예측을 합니다.
만약 예측이 틀리다면 재반입할 때까지 stall 하고, 과거를 업데이트합니다.
이때 Dynamic Branch Prediction을 자세히 설명해보겠습니다.
4. Dynamic Branch Prediction
어디까지나 예측이기 때문에, 틀릴 수 있다는 가정을 해야 합니다.
하지만 pipeline이 깊으면 깊을수록, control hazard의 페널티는 점점 커집니다.
그렇다면 예측을 최대한 잘해야겠죠?
앞선 설명에서 beq의 결정은 추가적인 register를 통하여 ID 단계에서 결정 난다고 설명드렸습니다.
다만 이때는 branch taken이 되면 stall이 발생하기 때문에, 어쩔 수 없이 최대한 taken을 예측해야 하고, 예측하는 방법 중에 두 가지가 있다고 설명드렸습니다.
예측이 실패하면 stall을 해야 하기 때문에, 예측도 잘해야 합니다.
아무튼 예측을 하기 위해선, 하드웨어에 또 다른 register를 추가해야 합니다.
이를 branch prediction buffer 혹은 branch history table이라고 합니다.
branch prediction buffer는 IF 단계에 있으며, 해당 buffer는 branch가 최근에 taken 되었는지 아닌지에 대한 bit 정보를 저장하고 있습니다.
따라서 저장되어 있는 bit에 따라 예측을 수행하고, 만약에 실패한다면 업데이트를 합니다.
두 가지 종류가 있는데, 1-bit predictor와 2-bit predictor가 있습니다.
1-bit predictor는 branch가 Taken이 된다면 bit를 0으로 바꿈으로써 다음 branch도 taken 될 것이라 판단합니다.
branch가 not taken이 된다면 bit를 1로 바꾸고, 다음 branch는 taken 되지 않을 것이라 판단합니다.
default는 1입니다.
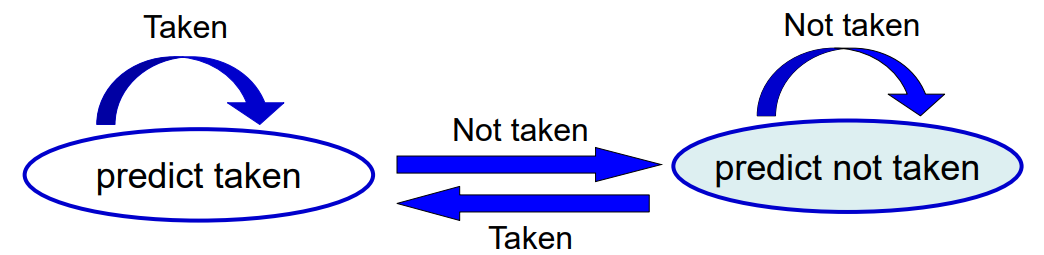
하지만 이 예측기도 문제가 있는데, inner loop가 있을 때 문제가 발생합니다.
inner loop가 계속 branch taken 되다가 어느 순간 빠져나올 때, 한 번의 miss가 발생합니다.
따라서 predictor는 bit를 1로 바꾸고, 다음 loop가 실행되지 않을 것이라 예측합니다.
하지만 outer loop가 실행이 된다면, predict는 틀리게 됩니다.
따라서 총 두 번의 miss가 발생합니다.
misspredict는 inner loop의 마지막 반복에서 발생하고, outer loop의 처음 시작에서 발생합니다.
이를 해결하기 위한 2-bit predictor가 있습니다.
bit가 두 개라면 총 4개의 상황을 저장할 수 있습니다.
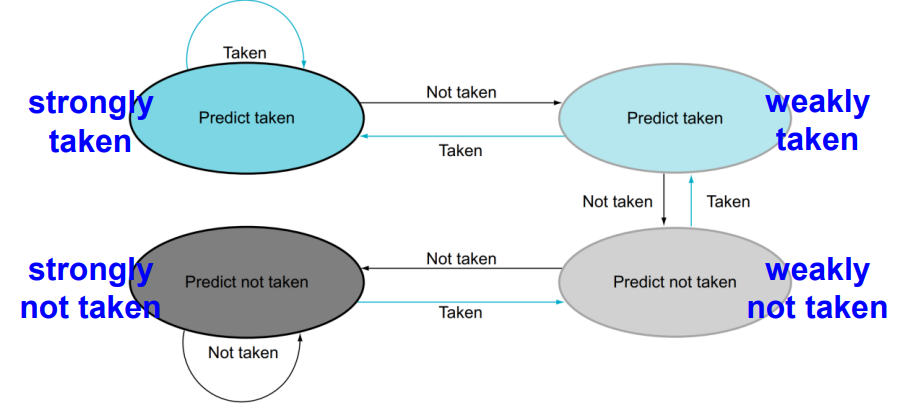
default는 weakly not taken입니다.
아무튼 두 번의 예측이 틀렸을 때, 비로소 예측이 바뀝니다.
1-bit predictor와 2-bit predictor를 비교해봅시다.
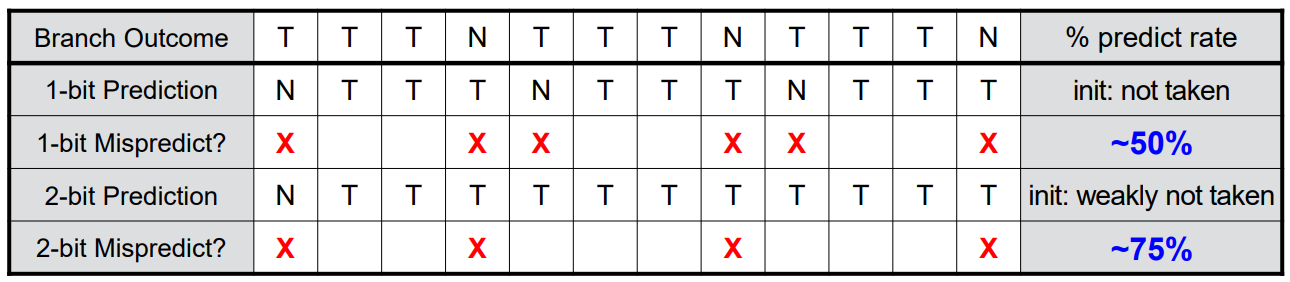
1-bit에 비하여 2-bit는 25%의 성공 확률 향상이 있는 모습입니다.
다음 글부터는 Pipeline의 Datapath에 대해서 글을 쓰겠습니다.
2022.11.16 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Pipelined Datapath
[컴퓨터 구조] Pipelined Datapath
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.01 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V의 기본적인 구현) [컴퓨터 구조] Basic Implementation of the RISC-V (RISC-V
hi-guten-tag.tistory.com
감사합니다.
지적 환영합니다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Pipelined Control (0) | 2022.11.16 |
|---|---|
| [컴퓨터 구조] Pipelined Datapath (2) | 2022.11.16 |
| [컴퓨터 구조] Data Hazard (2) | 2022.11.11 |
| [컴퓨터 구조] Structural Hazard (0) | 2022.11.10 |
| [컴퓨터 구조] Hazard (0) | 2022.11.10 |