1. Requests란?
Requests란 Python용 HTTP 라이브러리이다.
Python에서 특정 웹사이트에 HTTP 요청을 보내는 모듈이라고 생각하면 될 것 같다.
좀 더 쉽게 말해서 특정 웹사이트에 HTTP 요청을 보내 HTML 문서를 받아올 수 있는 라이브러리이다.
근데 정확히 말하면 얘가 가져오는 HTML 문서는 문서가 아닌 그냥 단순한 String이고,
뒤에서 배우는 BeautifulSoup에 의해 살아있는 HTML 문서로 바뀌게 된다.
2. 설치
터미널 창에 "pip install requests" 를 치면 알아서 설치가 된다.
근데 나는 파이참을 쓰기도 했고, 이때는 pip를 잘 몰라서 그냥
File -> Setting -> Project:Python -> Python Interpreter에 들어가서 '+'를 누르고 'requests' 라이브러리를 설치했다.

3. 기본적인 사용법
네이버에게 HTTP 요청을 보낸다고 하자.
네이버의 주소는 "http://naver.com"이다
코드 예시
import requests url = "http://naver.com"
response = requests.get(url)
print(response.status_code)
print(response.text)위의 코드를 설명하자면,
url = "http://naver.com"으로 설정했다.
이후, url 주소로 GET 요청(requests.get(url))을 보냈고, 서버에서는 그 요청을 받아서 요청자인 나에게 응답을 했다.
쉽게 말해 requests.get(url)을 통해 보낸 요청을 response라는 변수에 저장한 것이다.
(get 요청에 여러 파라미터를 추가할 수 있고, post 요청도 할 수 있는데, 이것은 나중에 시간이 된다면 추가로 정리하겠다.)
이후 response.status_code를 통해 정상적인 응답을 하였는지, 아니면 비정상적인 응답을 하였는지 나에게 알려준다.
보시다시피 print(response.status_code)를 입력하니 '200'이라는 숫자가 나왔다.
200이라는 숫자는 OK라는 의미로 정상적으로 응답을 했다는 의미이다.
만약 비정상적인 응답을 하면 200이 아닌 다른 숫자를 내보낼 것이다. 예를 들면 '403', '406'등등
(참고로 멜론 사이트 "https://www.melon.com"는 '406'에러가 뜬다)
그리고 이후에 print(response.text)를 하면
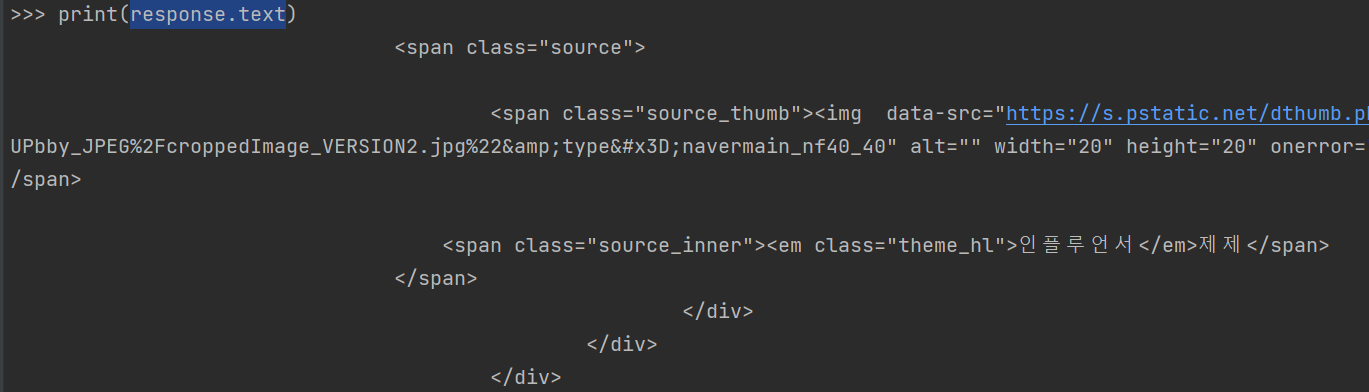
이런 식으로 네이버의 HTML 문서를 가져온다.
이게 다가 아니라 위의 일부분만 살짝 잘라서 가져온 것이다.
하여튼 엄청 많다.
어쨋든 중요한건 이렇게 resqusts를 통해 url에게 HTTP 요청을 할 수 있다는 점이다.
4. 조금 더 심화적인 사용법
요청을 받아와서 무언가를 하고 싶은데, 이게 정상적으로 받아온건지 아닌건지 판단하는 방법에는
첫 번째 방법으로는 if 문이 있다.
위에서 말했듯이 정상적으로 응답을 받으면 200이라는 숫자를 가져오는데, 이를 이용하면 된다.
if response.status_code == 200:
print("정상")
else:
print("비정상 [코드 : {}]".format(response.status_code))이런 식으로 해도 되고,
200 대신에 requests.codes.ok를 넣어도 된다.
if response.status_code == requests.codes.ok:
print("정상")
else:
print("비정상 [코드 : {}]".format(response.status_code))
만약 비정상이라면, 어떠한 작업을 할 수 없으니까 그냥 프로그램을 종료할 수도 있다.
그리고 두 번째 방법으로는 response.raise_for_status()가 있다.
raise_for_status()를 사용하면 정상적이라면 그냥 통과하지만, 비정상적일 경우에는 그 자리에서 프로그램에 오류를 내버리고, 프로그램을 종료한다.
그래서 보통 if문을 사용하지 않고, requests.get을 하자마자 바로 밑에 raise_for_status()를 사용한다.
url = "http://naver.com" response = requests.get(url) response.raise_for_status()이렇게 되면 비정상적인 응답에는 그대로 프로그램을 종료할 것이고, 아니라면 그냥 진행할 것이다.
이렇게 정상인지 아닌지 판단한 후에는 response.text를 이용해서 HTML 문서를 가져올 수가 있다.
네이버는 HTML 문서가 너무 길어서 간단하게 google을 가져왔다.
아래의 코드 예시를 보자
url = "http://google.com"
response = requests.get(url)
response.raise_for_status()
print(len(response.text))
print(response.text)
with open("google.html", "w", encoding="utf8") as google:
google.write(response.text)
len(response.text)를 통해 가져온 HTML 문서의 길이를 파악하고, response.text를 통해서 HTML 문서를 출력했다.
이후에 with 구문을 사용하여 google.html 문서에 HTML 문서를 저장했다.
저장된 문서를 보면,
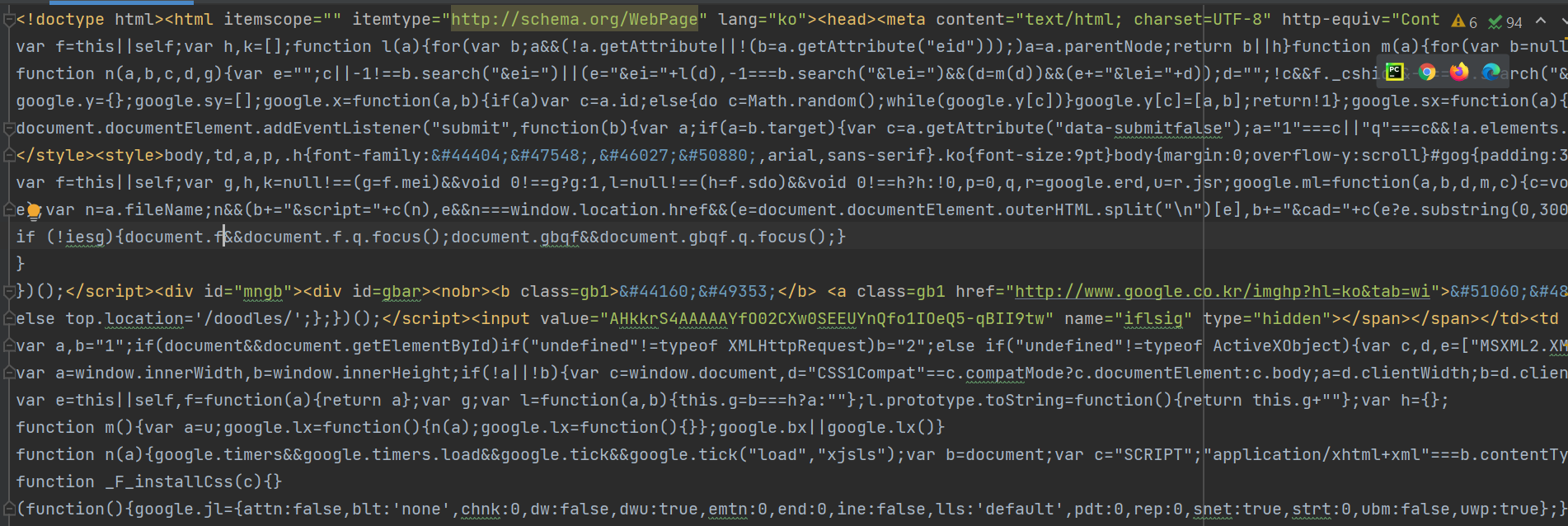
되게 보기 싫게 생겼다.
하여튼 이렇게 만들어진 HTML 문서를 오른쪽 상단에 있는 크롬 버튼을 누르면 실행할 수 있다.
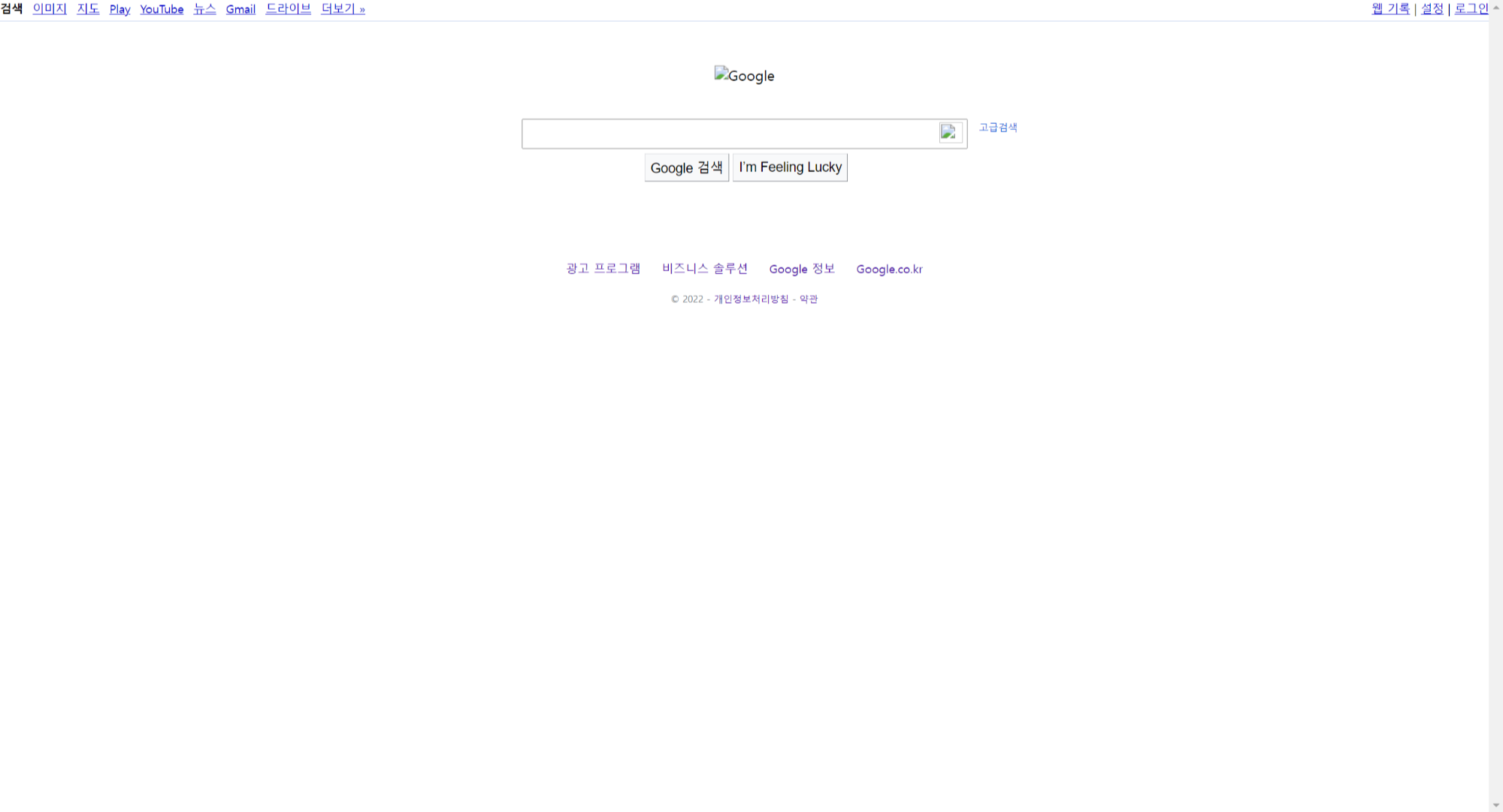
실제 우리가 아는 google 사이트와 굉장히 다르게 생겼다. 이는 CSS와 다른 여러가지 요소가 없기 때문이다.
하지만 HTML 문서는 제대로 받아온 것을 알 수 있다.
5. 요약
requests 모듈을 통해 해당 홈페이지에게 HTTP 요청을 보낼 수 있고, 응답을 저장할 수 있다.
response = requests.get(url)
받은 응답을 가지고, HTML 문서를 뽑아내던가, 응답 코드를 확인할 수 있다.
response.text
response.status_code
응답 코드의 종류를 알 수 있고, 종류에 따라 각기 다른 코드를 실행할 수 있다.
'200'은 정상 코드, '403', '406' 등등은 비정상 코드
if response.status_code == 200 || if response_status_code == requests.codes.ok
혹은
response.raise_for_status()
이렇게 얻은 응답으로 url의 HTML 문서의 텍스트를 얻을 수 있다.
참고 : 나도코딩
'Python Library > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링 - Python] Selenium 프레임워크 및 웹 드라이버 (0) | 2022.02.01 |
|---|---|
| [웹 크롤링 - Python] 응용 및 홈페이지 url 변경 크롤링 (2) | 2022.01.31 |
| [웹 크롤링 - Python] BeautifulSoup 사용법 (2) | 2022.01.28 |
| [웹 크롤링 - Python] BeautifulSoup4 라이브러리, lxml 모듈 (2) | 2022.01.28 |
| [웹 크롤링 - Python] User-Agent (1) | 2022.01.28 |