1. 간단한 응용
이번 시간에는 지금까지 배운 내용을 토대로 네이버 웹툰을 가져와보겠다.
가져올 네이버 웹툰은 김세훈 작가님의 '열렙전사'를 가져와보도록 하겠다.
가져올 내용은 제목과 링크, 그리고 별점을 가져오고 가져온 이후에는 평점의 평균을 내보도록 하겠다.
import requests
from bs4 import BeautifulSoup
# url은 네이버 웹툰의 열렙전사이다.
url = "https://comic.naver.com/webtoon/list?titleId=670152&weekday=sun"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"}
res = requests.get(url, headers=head)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
# html을 보면 알겠지만 제목은 td태그의 클래스명이 title이고, 평점은 div태그의 클래스명이 rating_type이다.
cartoons = soup.find_all("td", attrs={"class": "title"})
ratings = soup.find_all("div", attrs={"class": "rating_type"})
# 평점의 평균을 위한 avg이다.
avg = 0
# for문의 zip을 사용해 cartoon과 rating을 한꺼번에 돌렸다.
for cartoon, rating in zip(cartoons, ratings):
# 이 내용은 앞의 내용과 동일하다
title = cartoon.a.string
link = "https://comic.naver.com" + cartoon.a["href"]
rate = rating.strong.string
#이 부분이 약간 중요한데, 결국 내가 가져오는 HTML문서는 모두 string이라는 점이다. 숫자를 가져와도 결국 string이므로 다른 형태로의 변환이 필요하다.
avg += float(rate)
print(title, link, rate)
print("평점 평균 : {:.2f}".format(avg/len(cartoons)))
>>> 2부 128화 - 내가 돌아왔다!! https://comic.naver.com/webtoon/detail?titleId=670152&no=311&weekday=sun 9.59
2부 127화 - 사랑 https://comic.naver.com/webtoon/detail?titleId=670152&no=310&weekday=sun 9.51
2부 126화 - 집으로 https://comic.naver.com/webtoon/detail?titleId=670152&no=309&weekday=sun 9.93
2부 125화 - 함께 https://comic.naver.com/webtoon/detail?titleId=670152&no=308&weekday=sun 9.94
2부 124화 - 짊어진 것 https://comic.naver.com/webtoon/detail?titleId=670152&no=307&weekday=sun 9.86
2부 123화 - 넌 뒤졌다 https://comic.naver.com/webtoon/detail?titleId=670152&no=306&weekday=sun 9.91
2부 122화 - 빌릴게 https://comic.naver.com/webtoon/detail?titleId=670152&no=305&weekday=sun 9.89
2부 121화 - 우리 파티 https://comic.naver.com/webtoon/detail?titleId=670152&no=304&weekday=sun 9.92
2부 120화 - 겜블 https://comic.naver.com/webtoon/detail?titleId=670152&no=303&weekday=sun 9.84
2부 119화 - 노네임 + 특별편 https://comic.naver.com/webtoon/detail?titleId=670152&no=302&weekday=sun 9.85
평점 평균 : 9.82몇 줄 안되는 코드로 웹툰의 내용을 가져오는 것을 알 수 있다.
이 코드에서 생각해야할 부분은 결국 숫자를 가져와도 그것은 string이라는 점을 잊지 말아야 한다는 점이다.
2. url 변경
근데 내가 여기서 하나 간과한 점이 있다면, 결국 내가 가져온 페이지는 열렙전사의 1페이지라는 것이다.
열렙전사는 2022/01/31 기준으로 2부 128화까지 나왔고, 페이지로는 32페이지까지 나왔다.
(참고로 32페이지에서부터 1화이고, 1페이지가 2부 128화이다)
그렇다면 어떻게 1페이지부터 32페이지까지 가져올 수 있을까?
생각보다 간단하다.
우리가 맨 처음 열렙전사 페이지에 들어가면 url이 아마 "https://comic.naver.com/webtoon/list?titleId=670152" 일 것이다.

근데 우리가 2페이지로 넘어가면 url이 "https://comic.naver.com/webtoon/list?titleId=670152&page=2"로 변한다.
즉 뒤에 &page=2가 추가로 생성되는 것이다.
이를 이용하여 &page=1로 바꾸면
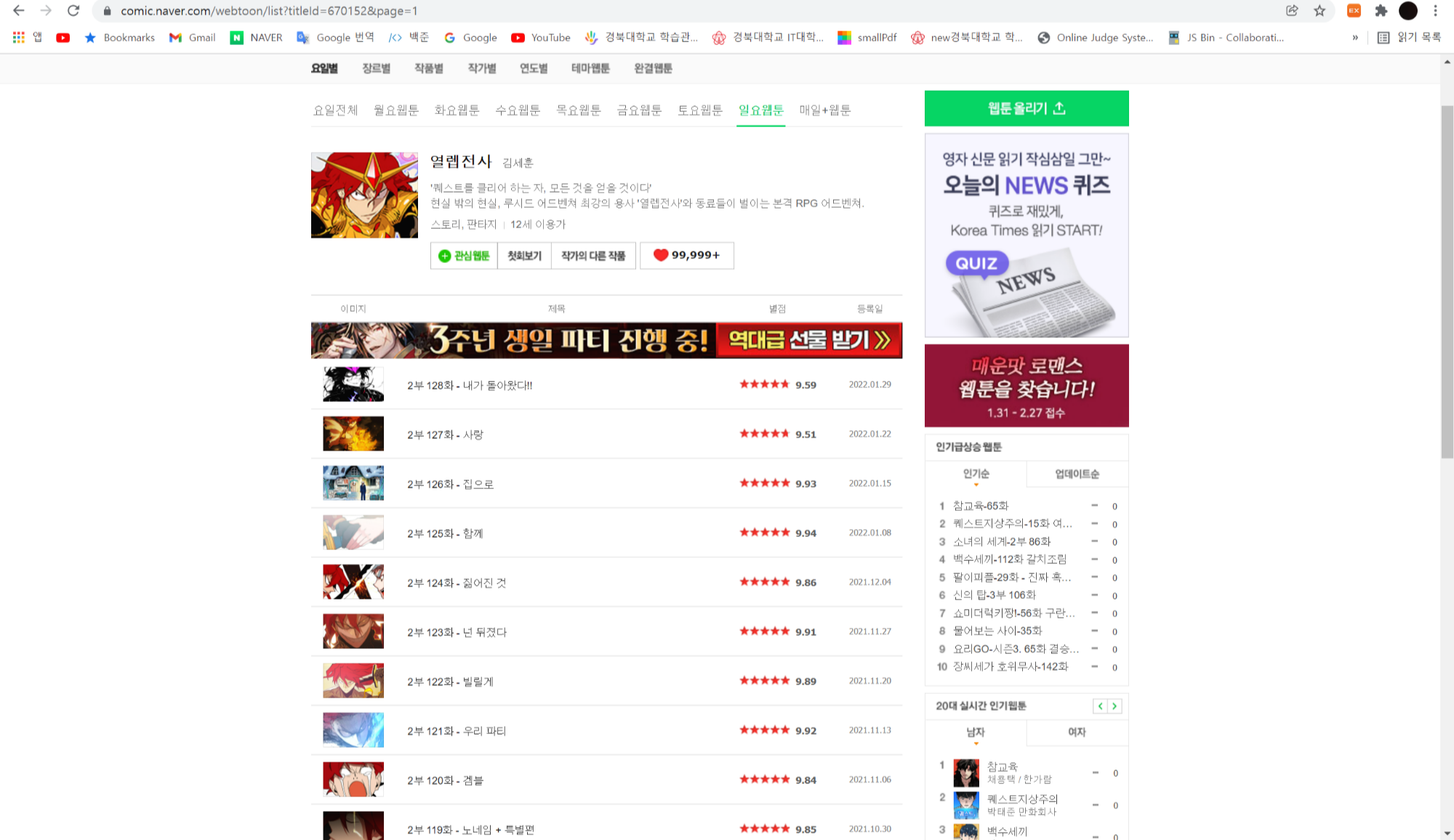
맨 처음의 페이지로 돌아온다.
이를 이용하여 &page=(1~32)를 이용하면 url을 바꿔가면서 크롤링 할 수 있다는 뜻이다.
근데 하면서 신기한 점이 있는데, page에 32가 넘는 숫자를 넣어도 32페이지가 그대로 나온다는 것이다.
이것은 네이버에서 의도적으로 해놓은 것 같은데, 하여튼 밑에 페이지를 보면 '이전, 다음'이 있는 것을 볼 수 있다.
이것을 이용해서 페이지를 바꾸는 법은 뒤에서 배울 selenium에서 할 것이다.
일단 우리는 url 끝 부분을 1~32로 바꾸면서 탐색해보자
파이썬을 할 줄 아는 사람이라면 format에 대해서 알 것이다.
format은 string에 내가 원하는 숫자를 넣을 수 있는 메소드인데, 이를 이용하여 url의 끝에 page숫자를 집어넣자.
url = "https://comic.naver.com/webtoon/list?titleId=670152&page={}".format(page)이런 식으로 해서 for문을 돌리면 각 page에 해당하는 url이 들어가서 크롤링 할 것이다.
그리고 생각해보니 find_all을 통해 가져온 리스트의 순서는 위에서 찾은 순서대로 가져오기 때문에, 높은 화에서 낮은 화 순으로 가져온다. 하지만 우리는 1화부터 오름차순으로 적어야하므로 reverse()를 통해 역순을 시켜주었다.
import requests
from bs4 import BeautifulSoup
# 평점의 평균을 위한 avg이다.
avg = 0
# 총 몇 화인지 세는 변수
episode_count = 0
# reversed를 통해 32페이지부터 1페이지까지 가져온다.
for page in reversed(range(1, 33)):
# url은 네이버 웹툰의 열렙전사이다.
# format을 통해 url의 끝 부분인 page 주소를 바꿔준다.
url = "https://comic.naver.com/webtoon/list?titleId=670152&page={}".format(page)
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"}
res = requests.get(url, headers=head)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
# html을 보면 알겠지만 제목은 td태그의 클래스명이 title이고, 평점은 div태그의 클래스명이 rating_type이다.
# reverse를 한 이유는 fidn_all을 통해 가져온 리스트의 순서는 위에서부터 가져오기 때문에 에피소드(화)의 순서가 역순이 되버린다.
# 그래서 reverse를 통해 에피소드의 순서를 정상적으로 바꾼 것이다.
cartoons = soup.find_all("td", attrs={"class": "title"})
cartoons.reverse()
ratings = soup.find_all("div", attrs={"class": "rating_type"})
ratings.reverse()
# for문의 zip을 사용해 cartoon과 rating을 한꺼번에 돌렸다.
for cartoon, rating in zip(cartoons, ratings):
# 이 내용은 앞의 내용과 동일하다
title = cartoon.a.string
link = "https://comic.naver.com" + cartoon.a["href"]
rate = rating.strong.string
# 이 부분이 약간 중요한데, 결국 내가 가져오는 HTML문서는 모두 string이라는 점이다. 숫자를 가져와도 결국 string이므로 다른 형태로의 변환이 필요하다.
avg += float(rate)
# 총 몇 화인지 세는 변수
episode_count += 1
print(title, link, rate)
print("평점 평균 : {:.2f}".format(avg/episode_count))
아마 이해하기 쉬울 것이다.
3. 요약
오늘 배운 내용은 find를 통해 숫자를 가져온다 하더라도 이것은 string이므로 따로 형변환 처리가 필요하다는 것
그리고, 리스트의 순서는 위에서 찾은 순서대로 가져온다는 것
마지막으로 format을 통해 url의 주소를 바꿔가며 크롤링을 할 수 있다는 점이다.
'Python Library > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링 - Python] Selenium 사용법 (0) | 2022.02.02 |
|---|---|
| [웹 크롤링 - Python] Selenium 프레임워크 및 웹 드라이버 (0) | 2022.02.01 |
| [웹 크롤링 - Python] BeautifulSoup 사용법 (2) | 2022.01.28 |
| [웹 크롤링 - Python] BeautifulSoup4 라이브러리, lxml 모듈 (2) | 2022.01.28 |
| [웹 크롤링 - Python] User-Agent (1) | 2022.01.28 |