앞의 글을 읽으시면 이해에 도움이 됩니다.
2022.01.28 - [Python Library/웹 크롤링] - [웹 크롤링 - Python] BeautifulSoup4 라이브러리, lxml 모듈
[웹 크롤링 - Python] BeautifulSoup4 라이브러리, lxml 모듈
1. BeautifulSoup과 lxml이란? BeautifulSoup이란 스크래핑을 하기위해 사용하는 패키지이고, lxml은 구문을 분석하기 위한 파서이다. 즉, BeautifulSoup은 response.text를 통해 가져온 HTML 문서를 탐색해서 원하는
hi-guten-tag.tistory.com
1. '.' 이용
'.'을 이용해서 보는 법이 있다.
예를 들어 앞에서 했던 네이버 웹툰을 생각해보자.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")여기서 네이버 웹툰 웹사이트의 제목, 즉 title을 뽑아보자
soup.title을 이용하여 뽑을 수 있다.
print(soup.title)
>>> <title>네이버 만화 > 요일별 웹툰 > 전체웹툰</title>이렇게 나온다.
실제로 네이버 웹툰의 title을 보면,

따라서 soup 객체을 통해 네이버 웹툰의 HTML의 element에 바로 접근을 할 수가 있다.
만약 여기서 텍스트 정보만 뽑아 오고 싶다면 soup.title.get_text() 혹은 soup.title.string을 사용하면 된다.
print(soup.title.get_text())
print(soup.title.string)
>>> 네이버 만화 > 요일별 웹툰 > 전체웹툰
>>> 네이버 만화 > 요일별 웹툰 > 전체웹툰둘 다 똑같이 네이버 만화 > 요일별 웹툰 > 전체 웹툰이 나오는 것을 알 수 있다.
get_text()와 string의 차이는 밑에서 설명하겠다.
만약 soup.a를 하면 어떻게 될까?
print(soup.a)
>>> <a href="#menu" onclick="document.getElementById('menu').tabIndex=-1;document.getElementById('menu').focus();return false;"><span>메인 메뉴로 바로가기</span></a>
되게 길어보이지만 결론적으로 말하면 HTML 문서에서 첫 번째로 a태그를 가지는 element 반환한다.
이때, soup.a.attrs(attribute)를 통해 이 element의 특성, 속성을 알 수 있다.
print(soup.a.attrs)
>>> {'href': '#menu', 'onclick': "document.getElementById('menu').tabIndex=-1;document.getElementById('menu').focus();return false;"}이것도 되게 길어보이지만 결국 딕셔너리 자료형으로 반환한다는 것을 알 수 있다.
따라서 딕셔너리를 통해서 검색을 할 수도 있다. a element의 href 속성 값 정보를 출력할 수 있다.
print(soup.a["href"])
print(soup.a.attrs["href"])
>>> #menu
>>> #menu둘 다 똑같이 #menu를 반환한다.
이러한 방법은 우리가 웹 사이트에 대해 잘 알고 있을 때, 쓸 수 있는 방법이다. 하지만 우리는 대부분 웹 사이트를 잘 알지 못하는 상태에서 크롤링을 시도할텐데, 이럴때는 '.'이 아닌 다른 방법을 사용해서 스크래핑을 해야한다.
2. find 이용
만약 우리가 네이버 웹툰에서 '웹툰 올리기' 버튼의 정보를 가져오고 싶다고 가정해보자.
참고로 오른쪽 위에 있다.
하여튼 저기 웹툰 올리기의 HTML을 보면,

이렇게 되어있는 걸 알 수 있다.
우리는 이때 find를 통해 어떻게 저 HTML 정보를 가져올 수 있을까??
soup.find('a')를 하면 soup.a 와 마찬가지로 맨 처음으로 나오는 a 태그를 가지는 element를 반환하게 된다.
이때, 우리는 find에 또 다른 파라미터를 추가할 수 있는데, 앞에서는 attrs를 단순히 속성 정보를 읽어오기 위해 사용했지만, find에서는 element를 조금 더 특정화 할 수 있는 파라미터로 이용할 수 있다.
'웹툰 올리기'의 class는 'Nbtn_upload' 임을 우리가 알 수 있다.
attrs에서 "class" 속성의 값이 "Nbtn_upload"을 가지는 a태그의 element를 가져올 수 있다.
어떻게 하냐면
soup.find('a', attrs={"class": "Nbtn_upload"})이렇게 하면 된다. attrs에 딕셔너리 자료형으로 {"class": "Nbtn_upload"}를 추가해주면 된다.
이렇게 해서 출력을 하면,
print(soup.find('a', attrs={"class": "Nbtn_upload"}))
>>> <a class="Nbtn_upload" href="/mypage/myActivity" onclick="nclk_v2(event,'olk.upload');">웹툰 올리기</a>
'웹툰 올리기'의 HTML 정보를 가져온다.
또한, 옆에 인기순위를 가져올 수도 있다.
인기 순위의 HTML을 보면,
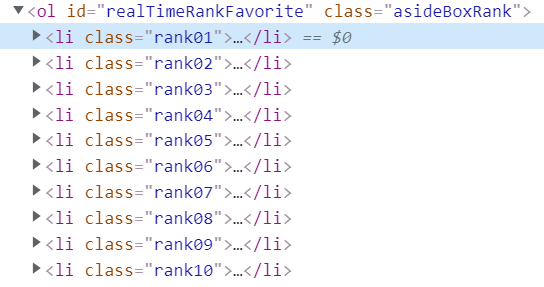
이므로, 'li' 태그를 가지는 element중에 class 명이 rank01인 것을 가져와 보겠다.
print(soup.find('li', attrs={"class": "rank01"}))
>>> <li class="rank01">
<a href="/webtoon/detail?titleId=641253&no=376" onclick="nclk_v2(event,'rnk*p.cont','641253','1')" title="외모지상주의-376화 일해회 (2계열사) [05]">외모지상주의-376화 일해회 (2계열사) [05]</a>
<span class="rankBox">
<img alt="변동없음" height="10" src="https://ssl.pstatic.net/static/comic/images/migration/common/arrow_no.gif" title="변동없음" width="7"/> 0
</span>
</li>실제로 해당하는 HTML 문서를 보면 저런 식으로 되어 있음을 알 수 있다.
근데 저렇게 찾아낸 HTML 또한, soup 객체로 활용할 수 있다.
rank1 = soup.find('li', attrs={"class": "rank01"})
print(rank1.a)
>>> <a href="/webtoon/detail?titleId=641253&no=376" onclick="nclk_v2(event,'rnk*p.cont','641253','1')" title="외모지상주의-376화 일해회 (2계열사) [05]">외모지상주의-376화 일해회 (2계열사) [05]</a>이런 식으로 사용 할 수 있다.
다른 방식으로 '태그'가 없이 쓸 수도 있긴하다. 근데 이 방법은 가급적 안 쓰는게 좋을 것 같다.
어쨋든 위와 같은 경우에는 해당 클래스 명을 가지는 특정 태그 element가 하나 밖에 없어서 가능한 일이다.
만약에 같은 클래스 명을 가지는 태그가 여러개 있다면 다른 방법을 써서 찾아야 한다.
3. find_all
최근 엄청난 인기를 가지고 있는 '쇼미더럭키짱!'을 예를 들어보겠다.
https://comic.naver.com/webtoon/list?titleId=783054&weekday=thu
쇼미더럭키짱!
고작 18살 나이로 부산을 꿇린 남자 강건마메마른 그의 가슴을 송두리째 불태울 존재가 나타났으니,그것은 '힙합'(Hip - hop)!래퍼가 되기 위해선 서울을 통합해야 하는 법!사나이 강건마! 오늘도
comic.naver.com
직접 들어가서 HTML 문서를 보면 알겠지만, 제목의 태그는 td이고, 클래스명은 title이다.
근데 모든 화가 똑같은 태그와 똑같은 클래스와 이름을 가진다.
이럴 때, find_all을 사용하여 모든 정보를 가지고 올 수 있다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/list?titleId=783054&weekday=thu"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")
cartoons = soup.find_all('td', attrs={"class": "title"})
for cartoon in cartoons:
print(cartoon.get_text())출력 내용은 다소 나쁜 내용이 들어가있어서 쓰지는 않았지만, 제목들이 출력되는 것을 알 수 있다.
중요한 것은 cartoons는 td태그를 가지고, class가 title인 모든 정보를 리스트 형태로 가지고 있다.
이후 for 문을 이용하여 하나씩 뽑아 출력하면 제목이 정상적으로 출력되는 것을 알 수 있다.
그냥 네이버 웹툰 메인 페이지에서 출력해도 정상적으로 출력된다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")
cartoons = soup.find_all('a', attrs={"class": "title"})
for cartoon in cartoons:
print(cartoon.get_text())출력 내용은 엄청 길어서 따로 가져오지는 않았다.
당연히 리스트니까 []참조를 통해서 가져올 수도 있다.
ex) cartoons[0].get_text()
4. 응용
네이버 웹툰 홈페이지에 있는 정보에 대한 제목과 링크를 가져오는 코드를 한 번 작성해보겠다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")
# 'a'태그를 가지고 class명이 title인 element를 모두 가져와 cartoons에 저장함
cartoons = soup.find_all('a', attrs={"class": "title"})
# cartoons에 저장된 element를 하나씩 뽑아내 출력함
for cartoon in cartoons:
# cartoon에서 텍스트를 읽어옴, 제목을 읽어오는 것
title = cartoon.get_text()
# cartoon에서 링크를 읽어옴, 딕셔너리 형태로 참조함
link = cartoon["href"]
# 얻어온 제목과 링크를 프린트함. 이때, link는 완전한 형태가 아니라서 https://comic.naver.com을 추가해줌
print(title, "https://comic.naver.com" + link)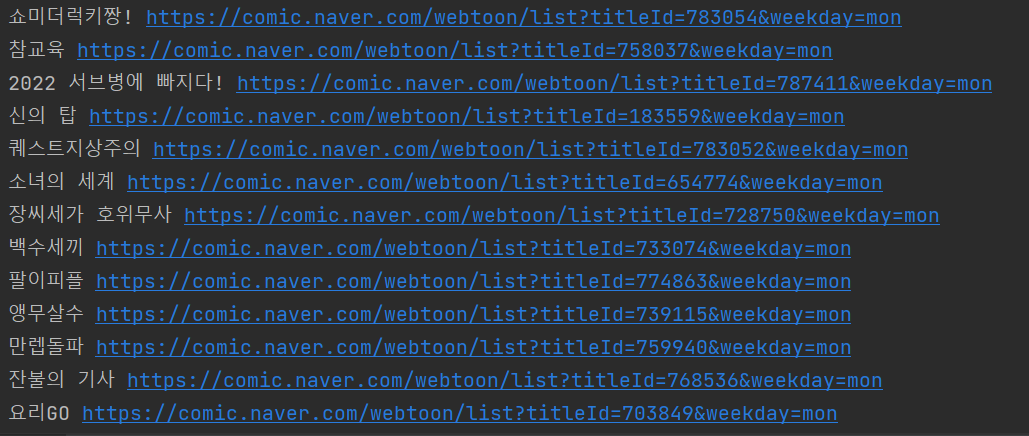
잘 가져오는 것을 볼 수 있다.
참고로 link 값은
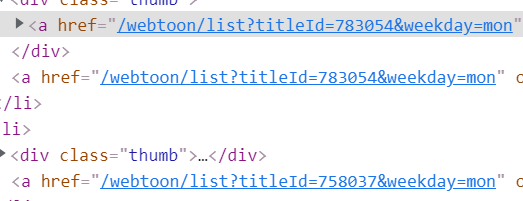
이런 식으로 되어있어서 우리가 완벽하게 만들어 줘야한다.
5. 번외(get_text()와 string의 차이)
get_text()
get_text는 해당 element에 있는 모든 text를 추출한다.
모든 text를 추출해 하나의 String으로 만든다.
string
진짜 string만 추출한다.
줄바꿈, 공백 등은 제거된 string만 추출한다.
get_text()는 하위 태그의 모든 텍스트를 추출해오고, string은 해당하는 태그에 string이 있으면 그것만 가져온다.
string은 정확한 위치에서 가져오고, 만약 자식 태그가 둘 이상이라면 무엇을 가져와야할지 모르기에 None을 반환한다.
하지만 자식태그가 하나이고, 그 자식 태그에 .string 값이 있으면 해당하는 자식의 string을 추출한다.
from bs4 import BeautifulSoup
html = \
"""
<div class="item-price">
<div class="o-price">
<span><27,000원</span>
</div>
<div class="s-price">
<strong><span>12,900원</span></strong>
</div>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
item_price = soup.find(attrs={"class", "item-price"})
o_price = soup.find(attrs={"class": "o-price"})
s_price = soup.find(attrs={"class": "s-price"})
print("get_text()를 이용해서 가져온 문자")
print(item_price.get_text())
print(o_price.get_text())
print(s_price.get_text())
print("string을 이용해서 가져온 문자")
print(item_price.string)
print(o_price.span.string)
print(s_price.strong.string)
>>> get_text()를 이용해서 가져온 문자
<27,000원
12,900원
<27,000원
12,900원
string을 이용해서 가져온 문자
None
<27,000원
12,900원보시다시피 get_text()는 쓸데 없는 \n까지 다 가져오는 것을 볼 수 있다.
item-price에서는 자식 태그가 두 개라 None을 반환한는 것도 볼 수 있다.
6. 요약
soup객체는 .(dot)을 통해서 참조할 수 있지만, 대부분의 경우 우리가 모르는 웹 사이트를 참조하기 때문에, find를 이용하는 것이 좋다.
find는 하나의 element만 가져오고, 다수의 element는 가져오지 않는다. 이때, 다수의 element중에서도 맨 처음 나오는 한 개의 element만 가지고 온다.
이때, find_all을 사용하면 해당하는 element를 모두 가져와 리스트 형태로 저장할 수 있다.
find와 find_all의 사용법은 다음과 같다.
ex) div태그 아래 class 명이 hello인 경우
soup.find("div", attrs={"class": "hello"}
soup.find_all("div", attrs={"class": "hello"}
다음 시간에는 다른 응용과 홈페이지 url을 바꾸면서 크롤링을 하는 방법에 대해 알아보겠다.
참고 : 나도코딩
'Python Library > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링 - Python] Selenium 프레임워크 및 웹 드라이버 (0) | 2022.02.01 |
|---|---|
| [웹 크롤링 - Python] 응용 및 홈페이지 url 변경 크롤링 (2) | 2022.01.31 |
| [웹 크롤링 - Python] BeautifulSoup4 라이브러리, lxml 모듈 (2) | 2022.01.28 |
| [웹 크롤링 - Python] User-Agent (1) | 2022.01.28 |
| [웹 크롤링 - Python] Requests 라이브러리 (0) | 2022.01.28 |