0. Abstract
- 해당 논문에서는 공간 초해상도를 향상하기 위해 비디오의 spatial, temporal 차원을 학습한 CNN을 제안한다.
- 연속적인 프레임은 motion cmpensate되고, 초해상화된 비디오 프레임을 결과로 내기 위한 입력으로 이용된다.
- 또한 하나의 CNN architecture에서 비디오 프레임을 연결하는 다양한 옵션에 대해서도 연구했다.
- 깊은 신경망의 학습을 위한 이미지 데이터베이스는 구할 수 있다.
- 하지만, 신경망을 학습하기 위한 충분한 수준의 비디오 데이터베이스는 구하기 어렵다.
- 우리는 이미지로 사전학습된 모델을 사용함으로써, 상대적으로 적은 비디오 데이터베이스를 사용해도 당대 최고의 성능을 내는 모델을 학습할 수 있었다.
1. Introduction
- UHD(3,840 x 2,048) TV가 등장하였지만, 대부분의 비디오 콘텐츠는 UHD를 감당할 수 없다.
- 따라서 FHD(1,920 x 1,080) 비디오 콘텐츠를 SR 해야하는 필요성이 생겼다.
- SR algorithm은 두 가지로 나뉜다. (model-based, learning-based, 그닥 중요한 내용은 아닌듯 하다.)
- Model-Based Algorithm은 LR에 추가 노이즈를 더하여 blurred, subsampled된 버전의 HR을 만드는 방식이다.
- 하지만 해당 Model-Based 방식은 ill-posed 하므로 정규화가 필요하다.
- Learning-Based 알고리즘은 대량의 LR, HR pair 데이터 셋에서 표현법을 배우거나, 이미지의 self-similarities(자기 유사성)을 추출한다.
- Dictionary based 접근 방식은 학습된 dictionary patches 혹은 atom의 선형 결합으로 이루어져 희소적으로 표현되는 image patch의 추정을 활용합니다.
- 관련 내용(Dictionary)
- 아무튼 해당 논문에서는 CNN을 활용한 SR을 소개하고 있습니다.
- CNN은 GPU를 활용하여 병렬화하여 효율적으로 학습을 할 수 있지만, 일반적인 신경망은 힘들다.
- 또한 한 번 CNN이 학습되면, 이미지를 SR것은 순수한 feed-forward 방식이므로 기존 방법보다 빠르다.
- 따라서 해당 논문에서는 CNN을 활용한 Video SR을 소개한다.
- 학습을 위한 Video의 quality 요구가 문제가 되기 때문에, 해당 논문에서는 이미지로 사전 학습한 CNN을 기반으로 적은 비디오 데이터베이스만 필요로 하는 알고리즘을 제안한다.
- 해당 논문에서 제안하는 CNN은 하나의 HR frame을 재구축하기 위해 여러개의 LR frame을 사용한다.
- 이때 시간 정보를 추출하기 위한 다양한 방법이 있다.
- 각각의 시간을 조정하는 세 개의 다른 architecture가 있다.
- 아무튼 이미지로 학습한 SR에서 VSR을 초기화하기 위해 filter coefficients의 결과를 활용하는 방법이 있다.
- 해당 방식은 정확도와 속도 측면에서 향상
- 또한 FIlter Symmetry Enforcement 방식도 있다.
- 해당 방식은 재구축된 비디오의 손실 없이도 20%가량 학습 시간을 줄임
- 마지막으로 adaptive motion compensation 방식도 있다.
- 해당 방식은 빠른 움직임과 motion blur를 처리함
2. Related Work
2.A Super-Resolution
- 대부분의 최고의 이미지 SR 알고리즘은 LR과 HR의 coupled dictionaries에서의 nonlinear mapping을 학습하는 learning-based algorithm을 사용한다.
- 이때 Overcomplete HR, LR dictionary는 HR, LR 이미지 patch로부터 학습된다.
- 관련 내용 (Overcomplete)
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gnoses&logNo=150178691245
- 각각의 LR 이미지는 LR dictionary의 atom의 희소 선형 결합으로 인해 표현될 수 있다.
- 이때 dictionary는 표현 가중치 (representation weight, common coefficient)와 couple이다.
- 아무튼 HR patch는 관찰된 LR patch의 희소 계수를 찾고, 그들을 HR dictionary에 적용함으로써 복구된다.
- 또 다른 HR 구축 기법은 Registration estimation인데, 이것은 LR 이미지 사이의 모션이 추정되면 이미지를 복구할 때, 즉 HR 이미지를 추정할 때 앞선 LR 이미지 사이의 모션을 사용하는 방식이다.
- 아무튼 SR을 하는데 있어서 dictionary 방식과 Optical Flow 방식이 쓰였다고만 알면 될 것 같다.
2.B Deep Learning-Based Image Reconstruction
- SRCNN에서는 dictionary based SR algorithm의 각 단계는 DNN의 층으로 재해석했다.
- 이때 표현되는 image patch의 size가 f x f이고, dictionary의 atom의 개수가 n일 때, 이는 입력 이미지에 kernel size f x f가 n개의 filter를 적용한 것이라 볼 수 있다.
- 이를 활용하여 LR에서 HR로의 nonlinear mapping을 직접적으로 학습하는 CNN을 만들었다.
- Cheng [20]은 CNN 구조를 사용하지 않아서 2차원 구조를 얻을 수 없다.
- Liao [21]은 motion compensation을 활용한 SR draft를 이용하였다. 해당 draft는 CNN에 결합이 되었다. 하지만 각 프레암마다 여러 단계의 motion compensation을 계산해야 하므로 과도한 계산량이 요구된다.
3. Video Super-Resolution With Convolutional Neural Network
3.A Single Frame/Image Super-Resolution

- SRCNN의 구조를 사용한다.
- 3개의 convolutional layer이 있고, H1, H2 뒤에는 ReLU가 온다.
- 첫 번째 convolutional layer에는 1 * f1 * f1 * C1, 두 번째는 C1 * f2 * f2 * C2, 마지막은 C2 * f3 * f3 * 1이 있다.
- 이때 첫 번째 Conv.Layer의 앞이 1인 이유는 이미지(사전학습)기 때문에 하나의 입력 값이 들어오기 때문이다.
- 마지막은 output이 하나의 커널인데 이는 이미지를 얻기 위해서이다.
- 이때 SRCNN이기 때문에 input과 output의 해상도는 동일하다.
- 추가적으로 일반적인 이미지 분류 아키텍쳐는 종종 pooling과 normalization layer을 사용하는데, 이는 작은 변화나 뒤틀림에 조금의 불변성을 부여한다. (일반적인 경우)
- 하지만 SR에서는 그들을 압축하기 보다는 이미지 디테일을 원하기 때문에 pooling, normlization은 배제하였다.
3.B Video Super-Resolution Architectures
- VSR의 복구 과정에 이웃하는 프레임을 넣는것은 도움이 된다.
- 프레임 사이의 motion이 복구 과정에서 modeled, estimated되고, 추가적인 정보들이 프레임 사이의 subpixel motion들로 인해 얻어진다.
- VSR을 위하여 해당 논문에서는 이웃하는 프레임을 process에 넣었다.

- 과거, 현재, 미래 시점의 프레임을 넣었다. (t-1, t, t+1)
- 이때 시점들을 합치는 세 가지 방법이 있는데, a, b, c가 각각 이들을 나타낸다.
- single input frame에서는 차원이 1 * M * N(M = width, N = height)이다.
- 하지만 a architecture에서의 Layer 1은 처음 Conv.Layer가 적용되기 전에 concat이 되므로 3 * M * N이 된다.
- b, c architecture도 비슷한 방식으로 다른 Layer의 차원이 커진다.
- 그렇기 때문에 a에서는 filter 1은 3 * f1 * f1 * C1이 되고, b에서는 filter 2가 3 * C1 * f2 * f2 * C2가 된다.
- 해당 방식들을 모두 테스트 했다.
3. C Weight Transfer From Pretraining
- SRCNN을 전이 학습 하기 위해서는 fig1과 fig2의 구조가 완전히 동일해야 한다. (kernel width, height)
- 유일하게 다른 것은 input frame의 개수이므로 filter의 depth만 다르다.
- 해당 논문에서는 a를 예를 들어서 설명한다.
- a에서의 fig1과 fig2가 같은 것은 filter 2, filter 3가 같다. 따라서 해당 filter는 전이 학습이 가능하다.
- a에서의 fig1과 fig2가 유일하게 다른 점은 filter 1의 차원이다.
- 따라서 VSR의 모델과 사전 학습된 모델(Image SR)의 layer 1의 차원이 다르다는 것이 문제이다.
- 더 나아가 layer 1의 결과로 얻어지는 데이터는 Image SR과 동일해야 한다. 왜냐하면 layer 2와 layer 3는 Image SR과 동일하게 유지되기 때문이다.
- 이를 증명하기 위하여 VSR에 3개의 연속적인 사진이 아닌 동일한 시점의 프레임을 넣는다고 가정한다.
- 따라서 VSR의 결과는 Image SR과 동일할 것이다.
- 왜냐하면 VSR의 layer 2와 layer 3은 image SR과 동일하기 때문이다.
- 그렇다면 이제 남은 것은 layer 1을 통하여 나오는 layer 2의 input data가 Image SR과 동일하다는 것만 확인하면 된다.

- 해당 수식이 Image SR에서 layer 1의 output을 계산하는 수식이다.
- M * N * C의 차원을 가지고 있고, C는 kernel의 개수이다.
- w는 filter의 가중치, b는 biases이고, t는 frame의 시간이다.
- 이때 weight 차원은 M * N * 1 * C인데, 세 번째 차원이 1인 이유는 하나의 단일 사진을 넣기 때문이다.
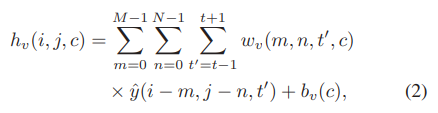
- 같은 데이터가 VSR에 들어갔을 때의 수식이다.
- 이때는 t를 3개의 시점으로 나누어서 계산해야 한다.
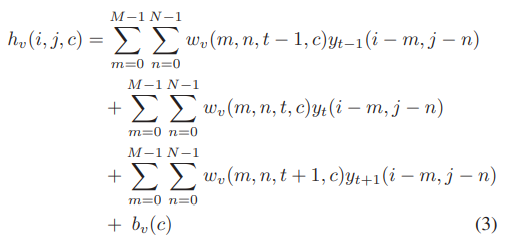
- 해당 수식들을 풀어서 전개한다면 위와 같은 수식이 나온다.
- 이때 y_t-1, y_t+1을 y_t로 바꾼다면 방정식 1과 같은 결과가 나온다. (물론 아래의 수식이 충족 되어야 한다.)
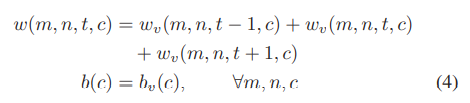
- 따라서 수식 1은 수식 4의 조건하에 수식 3을 변형한 것이라 볼 수 있다.
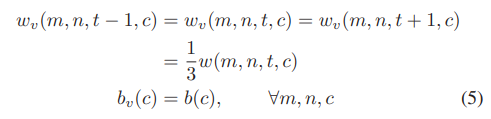
- 그러므로 해당 방정식은 첫 번째 filter를 통과하기 전에 3개의 이미지를 평균화 하는 것으로 볼 수 있다.
- 같은 방정식이 b나 c architecture에 적용될 수 있다.
- 따라서 해당 방정식들을 통해 image SR로 사전 학습한 모델을 VSR에 전이학습 할 수 있다는 것을 증명하였다.
3.D FIlter Symmetry Enforcement (FSE)
- 이상적인 motion compensated frame은 그것이 참조한 frame과 동일할 것이다.
- 그러므로 모든 입력 frame은 동일할 것이다.
- 하지만 가장 진보화된 optical flow도 오류를 피해갈 수는 없다.
- 만약 우리가 비디오의 각 frame을 SR 한다면 각 프레임은 t, t-1, t+1 시점의 프레임에 위치할 것이다.
- 따라서 t-1에서 t까지의 MC(motion compensation) Error와 t+1에서 t까지의 MC는 동일할 것이다.
- 그러므로 해당 모델이 결국 symmetric filter를 학습할 것이라 예상한다.
- 즉 t-1과 t+1 filter가 동일한 가중치를 가지게 된다는 의미이다.
- (나의 생각) : t-1 시점의 frame A가 있고, t 시점의 B가 있다고 가정하자. 이때 A(t-1) -> B(t)로 가는 MC error : C1가 있을 것이다.시간에 따라서 A는 t 시점으로, B는 t+1 시점으로 input 될 것이다. 이때 A(t) -> B(t+1)로 가는 MC error : C2가 있을 것인데, 통상적으로 C1과 C2는 같을 수 밖에 없다. 따라서 모델은 대칭되는 filter를 동일하게 학습할 것이다.
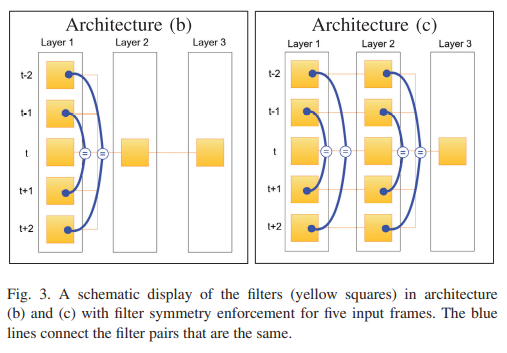
- 따라서 대칭되게 필터를 적용하여서 같은 가중치를 공유하게 하였다.
3.E Motion Compensation
- 많은 optical flow 알고리즘 중에 논문에서는 Druleas algorithm을 선택했다.
- Adaptive Motion Compensation : MC는 모션이 크거나 blurred 되었을 때 어려워진다. 이것은 HR로 재구축 할 때 의도하지 않은 경계에 영향을 미치고, 그러므로 성능을 하락시킨다.
- 그렇기 때문에 해당 논문에서는 adaptive motion compensation (AMC)를 제안한다.
- AMC의 수식은 아래와 같다.
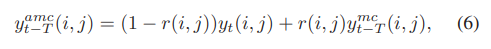
- r(i, j)는 두 개의 이웃하는 프레임 사이의 convex combination을 조절한다.
- y_t는 중심의 프레임이고, y_t-T는 MC된 이웃 프레임이다.
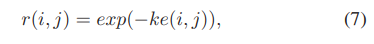
- k는 상수이고, e(i, j)는 MC error이다.
- MC error는 large motion, occlusion, blurring 등에 의해 발생된다.
- 즉 i, j (둘 사이의 교집합이 되는 부분)가 모션의 경계에 있을 때 에러가 크게 발생한다.
- 해당 수식에서 알 수 있듯이 error가 커지면 r은 작아진다.
- 그렇게 된다면 이웃하는 프레임의 영향은 작아지고, 현재의 프레임의 영향이 커지게 된다.
4. Experimental Section
- 3개의 SR architecture를 비교하고, pretraining의 영향, FSE, motion compensation에 대해서 실험했다.
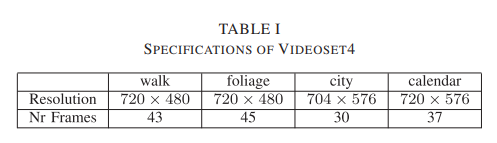
4.A Datasets
- 딱히 중요한 내용은 아닌 듯 하다.
4.B CNN Model Parameters
- layer 1과 layer 2에는 ReLU가 따라온다.
- layer 1에는 size 9 * 9의 kernel이 64개가 따라온다.
- layer 2에는 size 5 * 5의 kernel이 32개 따라온다.
- 마지막은 5 * 5 size 커널 하나
4.C Training Procedure
- PSNR, SSIM을 기준으로 측정하였다.
- 5개의 연속된 frame을 input하였다.
- 손실 함수는 PSNR로 하였다.
- 1, 2번째 프레임은 스킵하였다. 그렇게 함으로써 5개의 연속적인 프레임이 가능하기 때문이다.
4.D Comparison to the State-of-the-Art
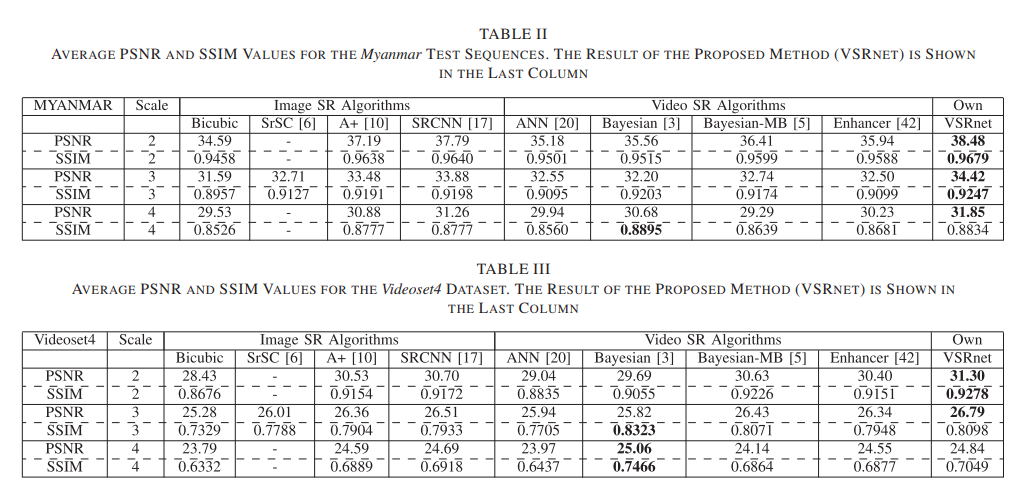
- Bayesian 방식도 좋게 나왔지만, 낮은 upscailing factor에서는 VSR이 좋은 결과를 냈다.
- 낮은 upscaling factor에서는 조금 더 정확한 MC 때문에 더 좋은 결과를 냈다고 예상한다.

- Upscailing factor이 4일 때
- VSRnet이 다른 알고리즘에 비해 문이 조금 더 잘 재구성 된 것을 볼 수 있다. (흠...난 잘 모르겠다)

- Upscailing Factor이 2일 때
- 확실히 VSRnet이 다른 알고리즘에 비해 blur가 덜 한 것을 볼 수 있다.
4.E Architecture Comparison
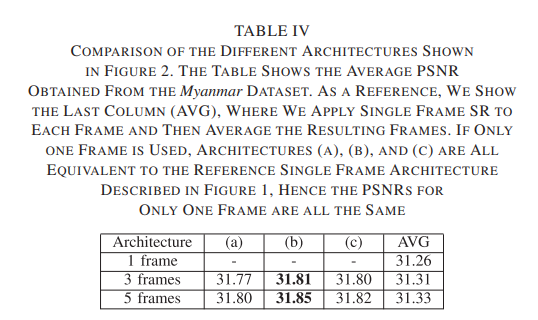
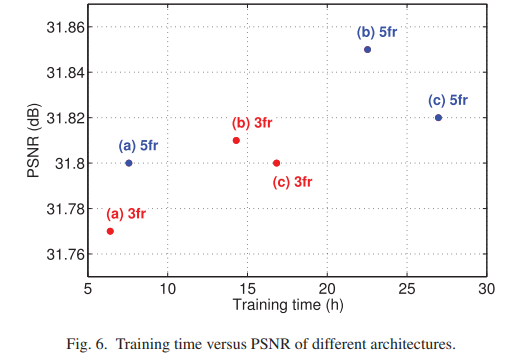
- Table IV에는 single frame SR 이상의 architecture의 장점을 소개한다.
- fig 6에서는 frame 개수와 학습 시간에 대해 나온다.
- 같은 architecture라도 input frame 수가 늘어나면 학습 시간과 PSNR이 높아진다.
- 또한 a -> b -> c로 갈 수록 학습 시간이 길어지는데, 이는 더 많은 가중치가 있기 때문이다.
- 위 그림을 보아 b가 가장 좋은 architecture임을 알 수 있다.
4.F Pretraining

- 위 사진은 b architecture의 upscale factor 3으로, Pretraining하고, 200,000번의 iteration 학습을 한 첫 번째 필터의 모습이다.
- 밑에는 Non-Pretraining, 400,000번의 iteration 학습을 한 모델
- 사전 학습이 비록 적은 iteration을 가졌지만 t-1, t, t+1의 filter의 모습이 매우 흡사함을 알 수 있다.
- 하지만 사전 학습을 하지 않은 filter의 모습은 흡사하지 않다.
- 왜냐하면 independent random initialization of the filter coefficient value 때문이다.
- 위의 그림에서 볼 수 있듯이 사전 학습을 하지 않은 filter의 경우 죽은 필터가 더 많이 보인다.
- 왜냐하면 ReLU Unit이 있기 때문이다.
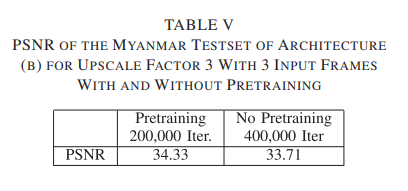
- PSNR에 아주 큰 영향을 끼친 모습을 볼 수 있다.
4.G Filter Symmetry Enforcement
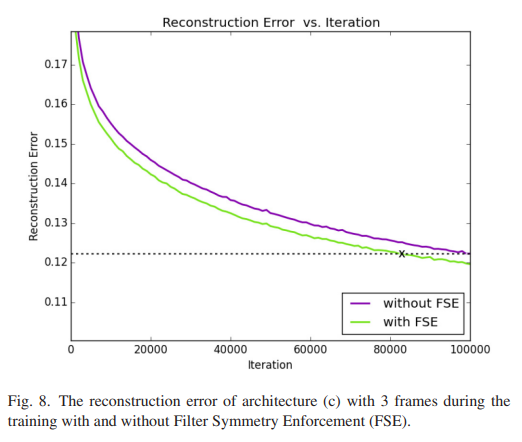
- FSE를 사용함으로써 약 20%의 학습 속도 향상이 보였다.
- 학습에 있어서 빠른 수렴은 unknown 가중치를 줄였다고 설명될 수 있다.
4.H Motion Compensation (MC)

- fig 9에서 어두운 부분이 r-value image이다. 어두운 부분일수록 작은 r이고, 높은 에러 값을 가졌다.
- 즉 비둘기가 날아가거나 손을 흔드는 빠른 motion일수록 높은 에러 값을 가지므로 주변의 frame보다 center frame을 조금 더 많이 사용함을 알 수 있다.
- fig 10에서 보시다시피 그냥 MC나 bayesian을 사용했을 때 이미지에 작은 dot가 있음을 볼 수 있고, AMC를 사용했을 때 비교적 좋은 결과를 냈음을 알 수 있다.
4.I Excution Time Analysis
- 그냥 GPU 어쩌고 하는 내용
5. Conclusion
- 해당 논문에서는 CNN을 이용한 SR algorithm을 소개했다.
- 우리가 제안한 CNN은 공간뿐만 아니라 시간 정보도 활용한다.
- 우리는 다른 architecture도 조사했으며, 그들의 장점과 단점도 보여줬다.
- Motion Compensated input frame, filter symmetry enforcement, pretraining method을 사용함으로써, 우리는 복원(SR)의 품질을 올릴 수 있었으며, 학습 시간도 단축했다.
- 최종적으로 우리는 motion blur, fast moving object를 다루기 위한 Adaptive motion compensation 방법을 소개했다.
- 우리는 Video SR에서 현재 최고의 성능을 능가하는 알고리즘을 보였다.
6. 논문 분석
- 생각보다 motion compensate, filter symmetry enforcement, optical flow, dictionary method 등을 알 수 있어서 좋았다. 자세히는 알지 못했지만, 대략적으로 CV에 이런 개념들이 있다는 점이 좋았다.
- 단점으로는 filter symmetry에서 t, t-1, t+1의 관계의 설명이 조금 부족했다. 추가적으로 내가 MC나 optical flow, dictionary method에 대한 지식이 부족해서 아쉬웠다.