0. Abstract
- 더 깊고 더 빠른 CNN을 사용하여 빠르고 정확한 single image SR이 가능함에도 불구하고, 한 가지 큰 문제점이 있다.
- 큰 upscaling factor에서 어떻게 미세한 텍스쳐 디테일을 복구할 것인가에 대해서다.
- 최근 연구는 대부분 MSE(mean squared reconstruction error)를 최소화 하는데 초점을 맞추고 있다.
- 그 결과는 PSNR(peak signal-to-noise, 높을 수록 좋음, MSE와의 반비례)를 높이지만, 세부 정보(high-frequency detail)가 부족하고, 더 높은 해상도에서 시각적으로 기대되는 충실도와 일치하지 않는다는 것이 불만족스럽다.
- 즉, 해당 논문은 MSE, PSNR이 SR을 측정하는데 절대적으로 정확한 측정법이 아니라고 말하고 있다.
- 해당 논문에서는 SR을 위한 GAN인 SRGAN을 소개하고 있다.
- 또한 SRGAN은 4배 확대를 위한 최초의 프레임워크이다.
- 이를 위해 adversarial loss와 content loss를 혼합한 새로운 perceptual loss function을 제시한다.
- Adversarial loss는 우리의 솔루션을 초 해상도 이미지와 원본 이미지를 구별하기 위해 학습된 분별기(discriminator network)에 넣음으로써 자연스러운 이미지가 되게 한다.
- 추가적으로 픽셀 공간의 유사성 대신에 시각적 유사성으로부터 나오는 Content loss를 사용한다.
- SRGAN으로 얻은 MOS(mean-opinion-score, 직접 사람이 점수를 매기는 방식)는 시각적 퀄리티에 상당히 중요한 결과를 보였다.
- 또한 그 어떤 다른 최첨단의 기술보다도 원본 이미지에 가까운 점수를 얻어냈다.
1. Introduction
- SR(super-resolution)은 LR(low-resolution)로부터 HR(high-resolution)을 추정하는 매우 어려운 작업이고, 많은 응용 분야와 상당한 관심을 받고 있다.
- SR의 불충분한 결정은 높은 upscaling factor에서 보이는데, 이때 복구된 SR의 texture detail이 종종 부자연스럽다.
- 왜냐하면 SR algorithm의 최적화의 대상이 복구된 HR image와 원본의 차이인 MSE를 최소화하는 것에 있기 때문이다.
- 이것은 MSE를 낮게 함으로써, PSNR을 높이므로 편리하기 때문이다.
- 하지만 high texture detail에서 지각적으로 관련된 차이를 캡쳐하는 MSE(and PSNR)의 능력은 그들이 픽셀 단위의 이미지 차이로 정의되어 있으므로 제한적이다.
- 이는 다음 그림에 나타나 있으며, 높은 PSNR이 결코 더 좋은 SR 결과를 나타낸다고 볼 수 없다.

- 초 해상도 이미지와 원본 이미지의 차이가 적다는 것(PSNR이 높다는 것)은 원본 이미지와 차이가 거의 차이가 없다는 것인데, SRGAN이 육안으로 가장 유사하다는 것을 알 수 있다.
- 즉, PSNR과 MSE는 절대적인 측정 방법이 아니다.
- 우리는 이 작업에서 skip-connection이 있는 ResNet을 사용하고, 유일한 최적화 대상인 MSE에서 분리한 SRGAN을 사용한다.
- 또한, 참조된 HR 이미지와 솔루션이 지각적으로 판별하기 어려운 점을 향상하기 위해 VGG network의 high-level feature map을 사용하여 새로운 perceptual loss function을 사용한다.
- 기존의 알고리즘은 단순히 MSE를 사용한 것에 반해, SRGAN은 VGG network으로 부터 추출된 feature map을 사용하여 loss를 계산함
1.1 Related Work
1.1.1 Image Super-Resolution
- SR을 하기 위한 방법은 많이 있었다.
- 하지만 최근에는 CNN 기반의 SR algorithm이 훌륭한 성능을 내고 있다.
- bicubic 보간법을 사용하여 upscale을 하고, 세 개의 deep fully convoluional network에 end-to-end 학습을 함으로써 좋은 성능을 냈다.
- 그 뒤에 network 자체가 upscale filter를 학습하면 더 빠르고 더 정확한 성능을 낼 수 있다는 것이 보여졌다.
1.1.2 Design of convolutional neural network
- 현재의 computer vision 문제는 대부분 CNN을 통해 해결하고 있다.
- 이는 깊은 network architecture가 학습은 어렵지만, 높은 복잡성의 모델 매핑이 가능함에 따라 네트워크의 정확도를 상당히 많이 올리는 잠재성을 가지고 있다는 것을 보여준다.
- deep network architecture의 학습을 효율적으로 하기 위해, batch-nomalization을 사용하여 internal co-variate shift(단점으로는 gradient vanishing 혹은 폭주)에 대응한다.
- 최근에 소개된 또 다른 설계로는 residual blocks와 skip connection이 있다.
- skip-connection은 본질적으로 사소한 identity mapping modeling의 network architecture을 완화하지만, 잠재적으로 convolutional kernel을 표현하는 것은 어렵다.
- SISR을 하는데 있어서 보간법으로 미리 upscale해서 CNN에 넣는 것보다 upscaling filter를 사용하는 것이 정확도와 속도 면에서 더 효율적이라는 것이 밝혀졌다.
1.1.3 Loss Functions
- MSE와 같은 픽셀 단위 손실 함수는 손실된 세부 정보 디테일을 복구하는데 내재된 불확실성을 가지고 있다.
- MSE를 최소화 하는 것은 픽셀의 평균을 찾는 그럴듯한 솔루션이며, 이는 특히 지나치게 매끄러워지므로 시각적인 질감이 안 좋을 수 밖에 없다.
- 그에 반해 GAN은 자연스러운 이미지를 재구성하기 때문에 시각적으로 합리적인 솔루션이다.
- 다양한 손실 함수에 대한 시도가 있었다.
- 하지만 사전 학습된 VGG network으로부터 추출된 특징으로 유클라디안 차이를 계산하는 손실 함수는 SR이나 예술적 스타일 변환에서도 시각적으로 훨씬 좋은 결과를 냈다.
- 결론적으로 MSE 기반의 Loss function보다는 VGG에서 추출된 특징으로 계산하는 Loss function이 더 효율적이다.
1.2 Contributions
- 여기서는 비교를 위해 SR에서의 최고 성능, PSNR과 SSIM이 가장 높은 SRResNet을 사용했다.
- 또한 GAN 기반의 network이고, 새로운 perceptual loss에 의해 최적화 되는 SRGAN을 제안한다.
- 이때 MSE 기반의 content loss는 VGG network의 feature map에 의해 계산되는 loss로 대체 했다.
- 추가적으로 MOS를 사용했는데, SRGAN이 최고의 성능을 냈다.
2. Method
- \(I^{SR}\) : super resolved image
- \(I^{LR}\) : low-resolution image
- \(I^{HR}\) : high-resolution image
- 이때 \(I^{LR}\)은 \(I^{HR}\) Gaussian filter를 적용하여 생성한다.
- 주된 목표는 generating function인 G를 LR로부터 HR에 대응하는 이미지를 생성하게 학습하는 것이다.
- 이때 CNN은 \(\theta_G\)를 인수로 가지고 있다.

- 즉 해당 수식은 n번째 LR로부터 만들어낸 SR 이미지를 \(l^{SR}\)에 넣음으로써 loss를 계산하고, 이 loss들의 평균이 최소가 되는 \(\theta_G\)를 찾는 것이 목표이다.
- \(l^{SR}\) : perceptual loss function
2.1 Adversarial network architecture
Discriminator

- 이 수식을 이해하면 해당 덧셈이 최대가 되는 \(\theta_D\)를 찾는 것이 목표인데,
- 이를 위해서는 HR에 대해서는 높은 확률을, LR에 대해서는 낮은 확률을 부여해야 최대가 된다.
- 따라서 \(\theta_G\)는 해당 수식이 최소가 되게 만들어야 하고, \(\theta_D\)는 해당 수식이 최대가 되게 만들어야 한다.
- 그러므로 G는 최대한 원본 이미지와 비슷하게 생성하여 D가 구별할 수 없게 학습을 해야 하고,
- D는 최대한 구분을 잘함으로써 G가 좀 더 사실적인 이미지를 생성하게 만든다.
Generator & Discriminator Network Architecture

* 나중에 설명
2.2 Perceptual loss function
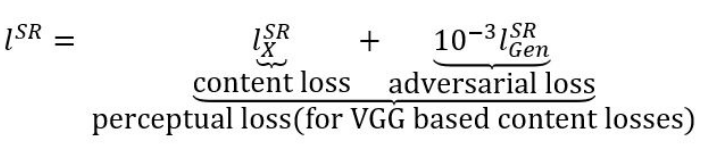
이때 content loss는 그대로 사용하지만, adversarial loss는 앞에 계수가 붙어서 사용되는데, 이는 adversarial loss의 영향도를 낮추기 위함이다.
2.2.1 Content Loss
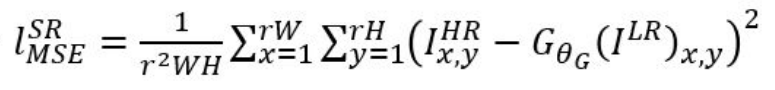
- 해당 수식은 MSE 기반의 SR loss를 계산하는데 가장 많이 이용되는 함수이다.
- 하지만 해당 함수를 기반으로 하는 SR 알고리즘은 세부 정보를 표현하기 어렵고, 시각적으로 불만족스럽다. (overly smooth)
- MSE loss를 적용하는 것 대신 VGG loss를 적용하기로 했는데, 수식은 아래와 같다.
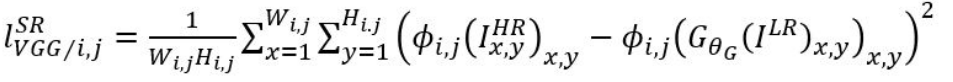
- VGG는 ReLU activation function을 사용한 사전 학습된 19 층의 VGG network를 사용하였다.
- 이때 \(\phi_{i, j} \)는 i번째 max pooling 전, j번째 convolution layer에서 추출된 값을 의미한다.
- 따라서 해당 두 개의 값의 유클라디안 거리를 계산한 loss를 사용한다.
2.2.2 Adversarial loss
- 앞선 content loss가 원본과의 content 차이를 나타낸다면, Adversarial loss는 시각적인 차이를 나타낸다.
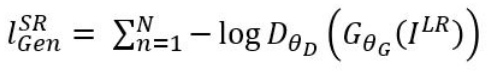
- 이는 G로 하여금 D를 좀 더 잘 속이게 하기 위한 loss라고 볼 수 있다.
- 추가적으로 위의 Discriminator의 뒤의 수식을 해당 수식으로 바꿔서 사용했다.
3. Experiments
- 다양한 데이터와 모델에 대해서 실험을 하였다.
- SRResNet : 손실함수로 MSE와 VGG/2,2 사용
- SRGAN
- 추가적으로 local optima를 피하기 위해 GAN을 학습할 때는 MSE 기반의 SRResNet을 사용하여 초기화 했다.
- MOS 테스트의 경우 26명의 실험자가 참여하였다.
- 또한 VGG/2,2 뿐만 아니라 다른 VGG/5,4에 대해서도 실험을 하였다.
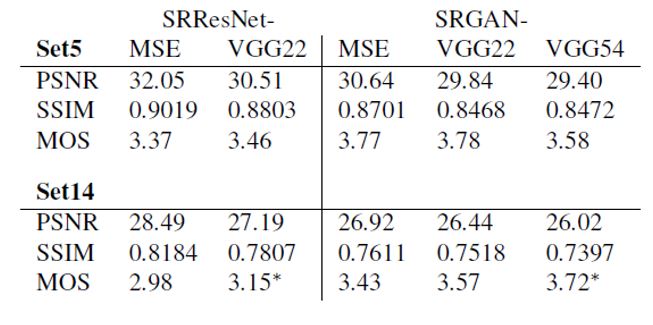
- 비록 MSE 기반의 SRResNet이 높은 PSNR과 SSIM을 보였음에도, 시각적으로 낮은 점수를 받았다.
- 또한 VGG/5,4가 VGG/2,2에 비해 높은 수준의 feature map을 생산하여 더 나은 텍스처 질감을 나타냈다.
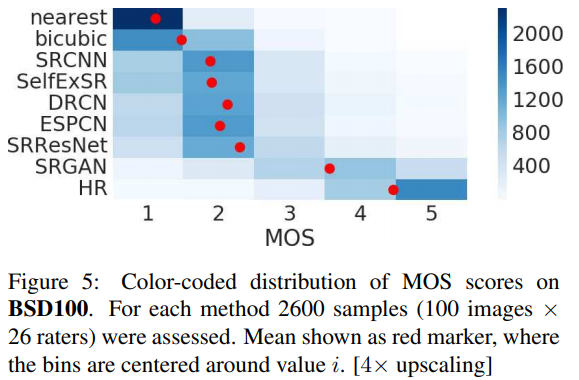
- 해당 figure에 따르면 SRGAN이 HR에 가장 가까운 MOS 점수를 받았다.
4. Discussion and future work
- 따라서 PSNR, SSIM은 인간의 visual system의 평가 기준이 되지 못한다.
- PSNR, SSIM은 시각적 퀄리티보다 계산의 효율성에 좀 더 중심을 둔 것이다.
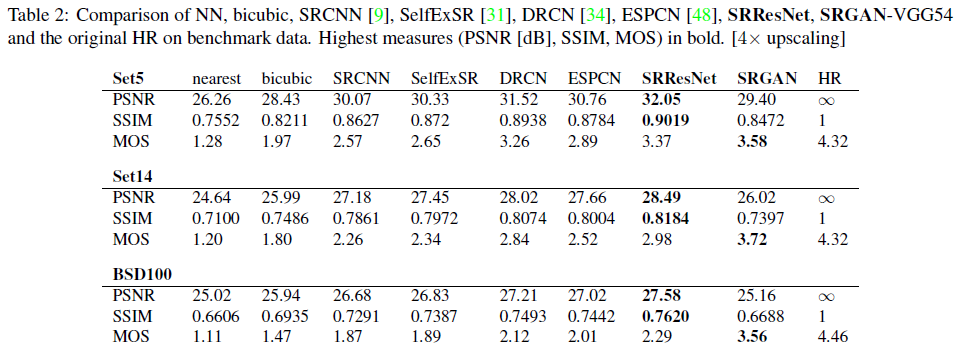
- 해당 표를 보면 PSNR이 높지 않아도 사람들이 인식하는 시각적인 텍스쳐의 품질은 좋을 수 있음을 나타낸다.
- 또한 VGG/5,4가 지각적으로 더 좋은 결과를 생산한다.
- 해당 논문에서는 feature map의 깊이가 content에 중점을 두고, adversarial loss가 texture detail에 중점을 둔다고 추측한다.
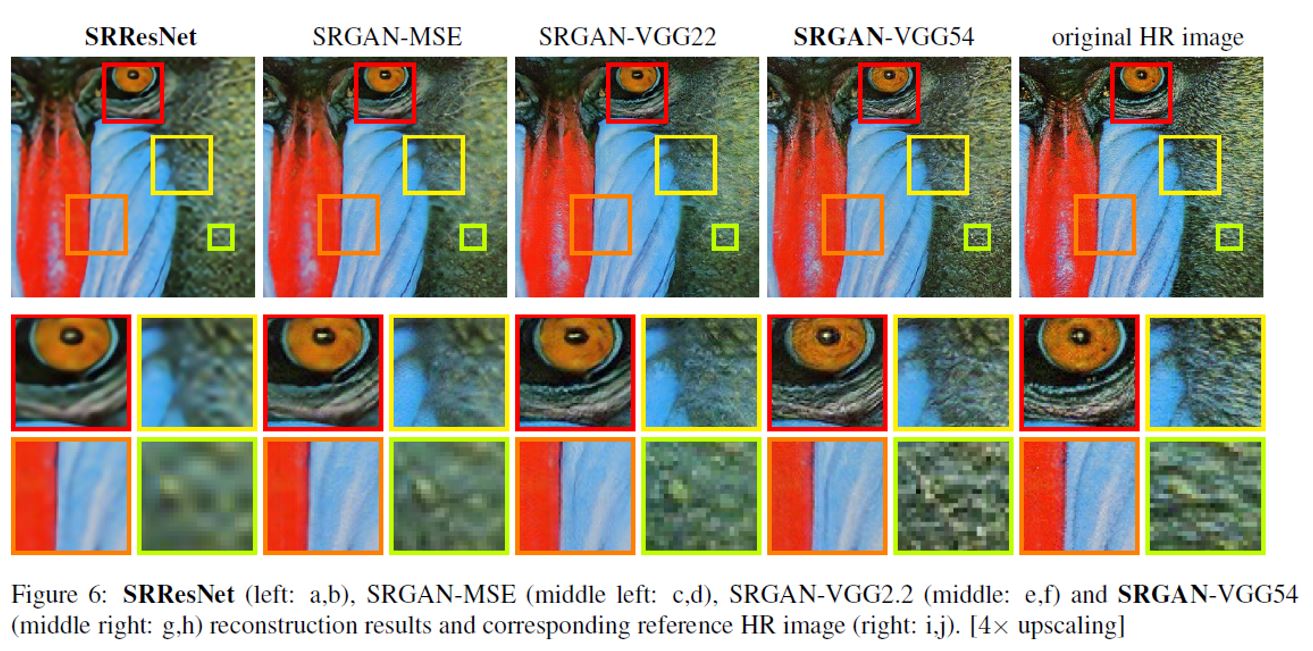
5. Concolusion
- SRResNet이 PSNR의 최고의 성능을 냈다.
- 하지만 해당 논문은 PSNR 중점의 SR 기법의 한계에 대해 밝혀냈으며, content loss와 adversarial loss 기반으로 학습한 GAN인 SRGAN을 소개했다.
- MOS testing을 통해 SRGAN이 최고의 결과를 냈다는 것이 보여졌다.