인간의 생성 능력을 예시로 들어보자면, 처음 가본 곳의 풍경을 그림으로 그립니다.
하지만 이 그림은 비슷하게 모방할 뿐, 정확히 같지는 않습니다. 의도적인 왜곡, 도구의 한계로 추상화하는 한계가 있습니다.
이를 인공지능에 적용하면 두 가지 모델이 나옵니다.
바로 분별 모델과 생성 모델입니다.
분별 모델은 얼굴, 표정을 보고 상대의 감정을 알아보는 등 이러한 능력을 말합니다.
인공지능은 분별 능력을 중심으로 발전해서, 앞에서 공부한 SVM, MLP, CNN, LSTM, RL 등 모두 분별 모델에 해당합니다.
생성 모델은 사람의 필체를 흉내 내는 인공지능 등이 대표적입니다.
딥러닝 기반 생성 모델인 GAN이 현재는 대표적인 생성 모델입니다.
https://thispersondoesnotexist.com/
This Person Does Not Exist
thispersondoesnotexist.com
GAN으로 생성한 사람의 얼굴입니다. 과연 무엇이 진짜일까요?
이처럼 현실 세계의 영상은 모양을 제어하는 고수준의 특징이 불분명합니다. 즉 0, 1, 2와 같은 숫자만 있는 것이 아니라, 사람의 얼굴, 자연의 영상 등 수많은 고수준 특징이 있습니다.
이 때문에 생성 모델을 설계하는 일은 무척이나 까다롭지만, 오토인코더와 GAN이 새로운 길을 열었습니다.
1. 오토인코더
오토 인코더는 입력 패턴과 출력 패턴이 같은 신경망입니다.
또한 레이블을 달 필요가 없는 비지도 학습입니다. 왜냐하면 세상에 존재하지 않는 것을 생성해야 하니까요.
고전적인 응용에서는 영상을 압축, 잡음을 제거하는 용도로 사용되었지만, 딥러닝에 응용되면서 특징을 추출하거나 생성 모델로서 활용되게 되었습니다.
1.1 오토인코더의 구조와 학습 방법
오토인코더는 입력 패턴 x를 받으면 유사한 x`를 출력하는 신경망입니다.
즉 x`은 최대한 x와 같아야 합니다.
이때 아무 제약이 없다면 은닉층의 노드 개수를 입력층과 같게 하고, 가중치를 1로 설정하면 됩니다.
그렇게 되면 원래 그림이 나오지만, 이러한 신경망은 무용지물입니다.
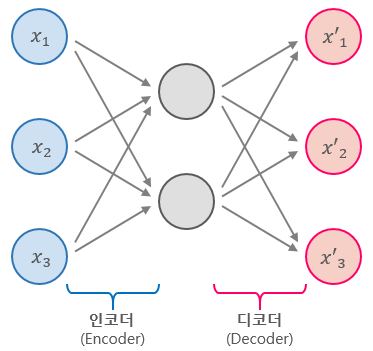
위의 그림처럼 은닉층의 뉴런 개수는 입력 층의 뉴런 개수보다 적습니다.
중간에 정보의 왜곡을 줌으로써 새로운 걸 창조해냅니다. 일부를 쥐어짬으로써 데이터의 일부를 날려버립니다.
즉, 인코더는 차원을 줄이고, 디코더는 차원을 회복합니다. 중간에 있는 공간을 잠복 공간(latent space)이라고 합니다.
내부의 표현이 입력 데이터보다 저차원이기 때문에 이런 오토인코더를 과소 완전(undercomplete)이라고 합니다.
과소 완전 오토인코더는 입력을 그대로 복사할 수 없으며, 입력과 똑같은 것을 출력하기 위해 학습합니다.
이는 입력 데이터에서 가장 중요한 특성을 학습하도록 만듭니다. 또한 중요하지 않은 것은 버리게 됩니다.
이때 오토인코더는 통째로 학습합니다. 하나의 Network로 이루어져서 GAN과 다르게 통째로 학습합니다.
시험공부를 해야 해서 생각보다 간단하게 정리를 했습니다.
나중에 시간이 된다면 더 자세한 오토인코더에 대해 작성하도록 하겠습니다.
감사합니다.
지적 환영합니다.