앞의 글을 읽으시면 이해에 도움이 됩니다.
2022.10.18 - [Computer Science/머신러닝] - [머신러닝 - 이론] Decision Tree (결정 트리)
[머신러닝 - 이론] Decision Tree (결정 트리)
1. Decision Tree (결정 트리)란? 결정 트리는 분류, 회귀 작업도 가능한 강력한 머신러닝 알고리즘입니다. 결정 트리는 if-else문을 사용하여 비교를 하는 간단한 알고리즘이며, 이름에서 알 수 있듯이
hi-guten-tag.tistory.com
1. Ensemble(앙상블)이란?
때로는 전문가 한 명의 답보다 많은 사람의 답이 나은 경우가 있습니다.
이를 대중의 지혜라고 합니다.
마찬가지로 예측기 여러 개로부터 예측을 수집하면 하나의 좋은 예측기보다 더 좋은 예측을 얻을 수 있을 것입니다.
이런 일련의 예측기를 앙상블이라고 부르기 때문에 이를 앙상블 학습(Ensemble Learning)이라고 합니다.
앙상블 학습을 하는 앙상블 방법(Ensemble Method)의 예를 들자면,
훈련 세트로부터 무작위로 다른 서브셋을 만들어 일련의 결정 트리 분류기를 훈련시킬 수 있습니다.
각각의 트리에 대한 예측 결과를 받아서, 가장 많은 선택을 받은 클래스를 예측으로 삼습니다.
결정 트리의 앙상블을 랜덤 포레스트(Random Forest)라고 합니다.
통상적으로 머신러닝 대회에서 우승하는 솔루션 중 여러 가지 앙상블 방법을 사용한 경우가 많습니다.
앙상블의 종류에는 배깅, 부스팅, 스태킹이 있습니다.
이번 글에서는 배깅에 대해 알아보고, 다음 글에서 부스팅, 스태킹에 대해 알아보겠습니다.
2. Voting Classifiers
배깅을 설명하기 위해서는 먼저 투표 기반 분류기에 대해 알아야 합니다.

더 좋은 분류기를 만드는 간단한 방법은 각 분류기의 예측을 모아서 가장 많이 선택되는 클래스를 예측하는 것입니다.
이렇게 다수결로 정해지는 분류기를 직접 투표(Hard Voting) 분류기라고 합니다.

사실 각각의 분류기가 약한 학습기(weak learner)일지라도,
(약한 학습기는 랜덤 추측보다 조금 더 높은 성능을 내는 분류기)
충분하게 많고 다양하다면 앙상블은 강한 학습기(strong learner)이 될 수 있습니다.
Hard Voting이 있다면, Soft Voting도 있습니다.
Soft Voting은 다수결의 선택이 아니라, 개별 분류기의 확률 예측을 평균 내어 확률이 가장 높은 클래스를 예측합니다.
물론 Soft Voting을 하기 위해서는 모든 분류기가 클래스의 확률을 예측할 수 있어야 합니다.
해당 방식은 확률이 높은 투표에 비중을 더 두기 때문에 Hard Voting보다 성능이 높습니다.
하지만 이때 주의해야 할 점은 모든 분류기가 완벽하게 독립적이고, 오차에 상관관계가 없어야 가능합니다.
왜냐면 같은 데이터로 훈련을 하기 때문에, 위의 가정이 없다면 같은 종류의 오차를 만들기 쉽기 때문입니다.
따라서 다양한 분류기를 얻는 한 가지 방법은 각기 다른 알고리즘으로 학습시키는 것입니다.
이렇게 하면 다른 종류의 오차를 만들 가능성이 높기 때문에 앙상블의 정확도를 향상시킵니다.
(다른 오차를 만들면 서로 중복되지 않기 때문에 해당 오차를 선택할 가능성이 적어짐)
다양한 분류기를 얻는 또 다른 방법은 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 것입니다.
훈련 세트에서 중복을 허용하여 샘플링하는 방식을 배깅(Bagging, 다른 말로 Bootstrp)이라고 하고,
중복을 허용하지 않고, 샘플링하는 방식을 페이스팅(Pasting)이라고 합니다.
3. Bagging / Pasting
중복을 허용하는 bootstrap을 사용할 때의 이미지는 아래와 같습니다.

모든 예측기가 훈련을 마치면 앙상블은 예측을 모아서 새로운 샘플에 대한 예측을 만듭니다.
분류일 때는 통계적 최빈값(statistical mode)를 이용하여 Hard Voting처럼 가장 많은 예측 결과를 계산하고,
회귀일 때는 평균을 계산합니다.
(만약 모든 예측기가 확률을 추정할 수 있다면, Soft Voting을 사용합니다.)
이때 개별 예측기는 원본 훈련 세트로 훈련하는 것보다 훨씬 크게 편향되어 있지만, 수집 함수를 통과하면 편향과 분산이 모두 감소합니다.
따라서 하나의 예측기를 훈련할 때와 비교해 편향은 비슷하지만, 분산은 줄어듭니다.
위의 그림에서 볼 수 있듯이 모든 예측기는 병렬로 학습을 할 수 있습니다.
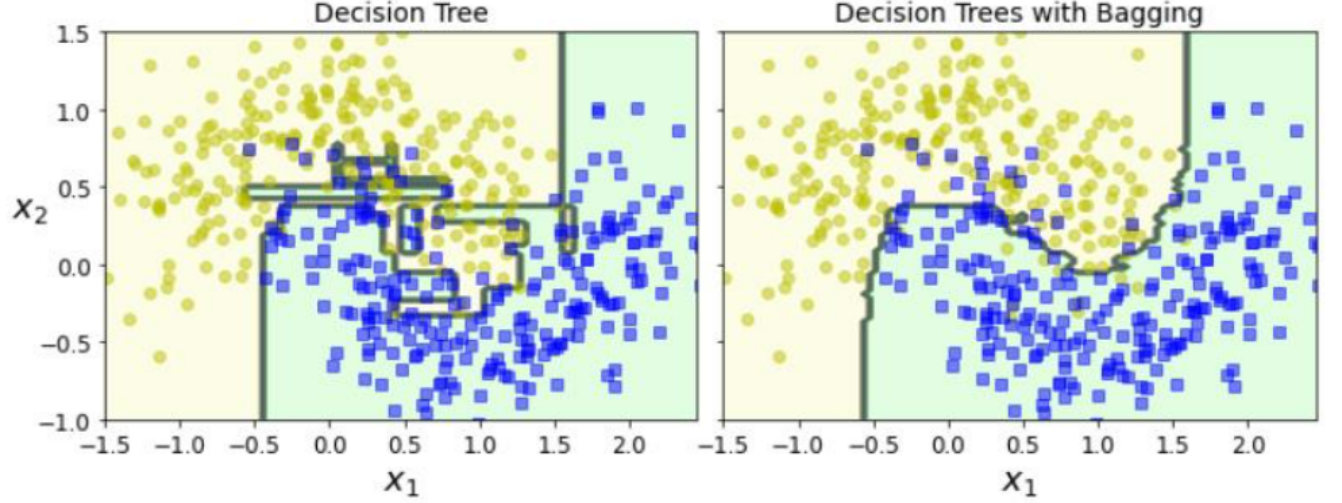
해당 그림에서 볼 수 있듯이 단일 결정 트리보다 앙상블의 예측이 일반화가 훨씬 잘된 것 같습니다.
앙상블은 비슷한 편향에서 더 작은 분산을 만듭니다.
오차 수가 거의 비슷하지만 결정 경계는 덜 불규칙합니다.
일반적으로 Bootstrapping 방식은 각 예측기가 학습하는 서브셋에 다양성을 증가시키므로, 배깅이 페이스팅보다 편향이 조금 더 높습니다.
하지만 다양성을 추가한다는 것은 예측기들의 상관 관계를 줄이므로 앙상블의 분산을 감소시킵니다.
일반적으로 배깅이 페이스팅보다 더 좋은 모델을 만든다고 하네요.
(랜덤성을 추가함으로써 다양하게 학습한다.
하지만 랜덤하게 함으로써 편향은 올라갈 수 있지만, 예측기들이 각기 학습하는 서브셋이 랜덤이기 때문에 예측기들 사이의 상관관계는 줄인다.)
다음 글에서는 결정 트리에 배깅 또는 페이스팅을 적용한 랜덤 포레스트와,
단순히 예측기를 모아서 진행하는 것이 아닌 예측기를 학습까지 하는 Boosting에 대해 알아보겠습니다.
2022.10.19 - [Computer Science/머신러닝] - [머신러닝 - 이론] Ensemble - Random Forest (앙상블 학습 - 랜덤 포레스트)
[머신러닝 - 이론] Ensemble - Random Forest (앙상블 학습 - 랜덤 포레스트)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.10.18 - [Computer Science/머신러닝] - [머신러닝 - 이론] Decision Tree (결정 트리) [머신러닝 - 이론] Decision Tree (결정 트리) 1. Decision Tre..
hi-guten-tag.tistory.com
2022.10.19 - [Computer Science/머신러닝] - [머신러닝 - 이론] Ensemble - Boosting (앙상블 학습 - 부스팅)
[머신러닝 - 이론] Ensemble - Boosting (앙상블 학습 - 부스팅)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.10.19 - [Computer Science/머신러닝] - [머신러닝 - 이론] Ensemble - Bagging (앙상블 학습 - 배깅) [머신러닝 - 이론] Ensemble - Bagging (앙상블 학습 - 배깅..
hi-guten-tag.tistory.com
감사합니다.
지적 환영합니다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝 - 이론] Ensemble - Boosting (앙상블 학습 - 부스팅) (0) | 2022.10.19 |
|---|---|
| [머신러닝 - 이론] Ensemble - Random Forest (앙상블 학습 - 랜덤 포레스트) (0) | 2022.10.19 |
| [머신러닝 - 이론] Decision Tree (결정 트리) (1) | 2022.10.18 |
| [머신러닝 - 이론] Softmax Regression (소프트맥스 회귀) (0) | 2022.10.18 |
| [머신러닝 - 이론] Logistic Regression (로지스틱 회귀) (0) | 2022.10.18 |