앞의 글을 읽으시면 이해에 도움이 됩니다.
2022.09.24 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블리어)
[컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블리어)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.09.23 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Introduction to Computre Architecture (컴퓨터 구조의 소개) [컴퓨터 구조] Introduction to Computer..
hi-guten-tag.tistory.com
1. Design Principle 1 : Simplicity favors regularity
add a, b, c
해당 명령어가 어셈블리어의 가장 기초라고 볼 수 있습니다.
RISC-V의 모든 산술 명령어는 세 개의 변수를 가지고 있습니다.
세 개의 변수는 두 개의 source, 한 개의 목적지로 나누어집니다.
예를 들어서 변수 b, c, d, e를 더하여 a에 넣고 싶다면 총 세 개의 명령어가 필요합니다.
add a, b, c // a = b + c
add a, a, d // a = a + d
add a, a, e // a = a + e
이러한 부분을 통하여 디자인의 원리에 대해 알 수 있습니다.
- Design Principle 1 : Simplicity favors regularity
이러한 규칙은 구현을 간단하게 만들고, 적은 비용으로 높은 성능을 내는 것이 가능합니다.
예를 들어서 f = (g + h) - (i + j)라는 명령어가 있을 때, 이를 어셈블리어 명령어로 바꿔본다면,
add t0, g, h // t0 = g + h
add t1, i, j // t1 = i + j
sub f, t0, t1 // f = t0 - t1
이렇게 규칙을 세움으로써 단순하게 명령어를 만들 수 있습니다.
2. Design Principle 2 : Smaller is Faster
그렇다면 앞의 add나 sub은 어떤 명령어인지 알겠는데, t0, g, h, ... 은 과연 무엇일까요?
해당 값들은 레지스터입니다.
레지스터는 하드웨어 디자인의 가장 기초적인 저장소입니다.
memory hierarchy의 가장 최상위에 위치한 계층입니다.
RISC-V는 32 x 32-bit register (x0 ~ x31)을 가지고 있습니다. (강의는 기준이 32bit임)
이때 레지스터는 가장 자주 접근되는 데이터를 사용하며, 32-bit data는 word라고 불립니다.
64-bit는 doubleword라고 불립니다.
레지스터는 매우 빠른 저장소입니다.
그렇다면 당연히 많은 게 좋을 텐데, 왜 32개만 사용할까요?
여기서 나오는 게 하드웨어 디자인의 두 번째 원리인
- Design Principle 2 : Smaller is Faster
입니다.
레지스터가 많을수록 clock cycle이 길어지고, 이는 곧 속도의 저하를 나타냅니다.
따라서 성능과 레지스터의 관계는 trade-off 관계라고 볼 수 있습니다.
근데 그렇다고 31개가 더 빠르지는 않다고 하네요.
세 번째 원리는 나중에 저기 뒤에 명령어의 타입에 대해 설명할 때 나옵니다.
3. Memory
3.1 Memory Operands
메인 메모리에는 수많은 배열이나 구조체 같은 복합 데이터가 있습니다.
register는 32개밖에 없어서 이러한 composite data를 수용하기에는 제한됩니다.
하지만 RISC-V의 모든 arithmetic operation은 오로지 레지스터에 있는 값들에만 적용할 수 있습니다.
따라서 이런 데이터를 메모리에서 레지스터로 가져오는 연산과, 레지스터의 값을 메모리로 저장하는 연산이 필요합니다.
RISC-V에서는 Load 명령어를 통하여 Memory -> Register을 지원하고,
Store 명령어를 통하여 Register -> Memory를 지원합니다.
Load와 Store 명령어를 Data Transfer Instruction이라고 하며, 레지스터와 메모리 사이의 데이터 운반을 담당합니다.
3.2 Memory Addressing
메모리에 접근하기 위해서는 instruction은 반드시 memory address를 지원해야 합니다.
메모리는 크고, 1차원 배열 형태이며, 주소가 0부터 시작하여 각각의 배열에 주소가 있습니다.
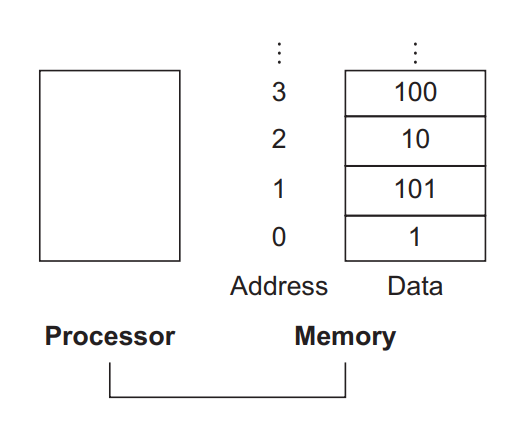
앞 글에서 설명드렸다시피, 데이터의 처리는 해당 architecture의 word 단위로 이루어집니다.
우리는 32-bit가 word인 architecture를 다루고 있으므로, 실질적인 메모리의 형태는 다음과 같습니다.

따라서 word의 byte address는 word 안에 포함된 4byte의 하나의 주소와 일치합니다.
여기서 나오는 게 있는데, 이렇게 word 단위로 데이터를 처리하고,
명령어를 수행한다는 것은 곧 특정 메모리의 주소에 접근할 때, 이진수의 끝자리가 00으로 끝난다는 것을 의미합니다.
3.3 Endian
Endian은 하나의 word 안에서 32-bit를 어떤 순서로 놓느냐에 대한 정의입니다.
RISC-V는 Littel Endian 방식을 사용하며, 이는 LSB(Least Significant Byte)가 least address of a word에 위치합니다.
LSB는 가장 하단에 있는 비트를 의미합니다.
0x00112233에서 LSB는 33이 됩니다.
MSB는 00이 됩니다.
따라서
- Big Endian : MSB is placed at the lowest address
- Little Endian : LSB is placed at the lowest address
가 됩니다.

사실 RISC-V에서는 word가 메모리에 정렬될 필요가 없으며, 4의 배수로 시작할 필요는 없습니다.
하지만 그래도 4의 배수로 접근하는 게 좋아요.
3.4 Memory Operand Example
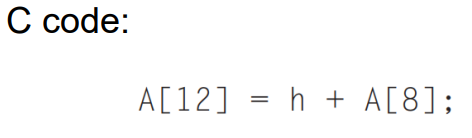
이런 코드가 있을 때,
h는 register x21에 있고,
A의 base address는 x22에 있다고 가정합시다.
순서는 다음과 같습니다.
A[8]을 register에 반입, h와 A[8]을 더하여 register에 저장, 해당 값을 A[12]에 저장
그러면 어셈블리어는 다음과 같습니다.
lw x9, 32(x22) // 시작 주소는 x22에 있고, 8번째 주소는 word byte * 8이므로 32, 따라서 x22 + 32를 하여 반입
add x9, x21, x9
sw x9, 48(x22)
쉽게 이해가 되시나요?
4. Register vs Memory
레지스터는 메모리보다 access 속도가 매우 빠릅니다.
또 arithmetic operation은 오로지 레지스터에 있는 값들로만 연산합니다.
그러면 상식적으로 많이 사용하는 값을 레지스터에 넣어놔야겠죠?
근데 레지스터가 부족하여 산술 연산을 해야 하는데, 해당 데이터가 메모리에 있으면 lw를 통하여 값을 반입해야 합니다.
이때 레지스터와 메모리의 반입 시간에 대한 그림이 아래에 나와 있습니다.

만약 연산을 해야하는데 레지스터에 값이 없으면 L1 cache로,
L1에도 없으면 L2, 또 없으면 L3로 갔다가 최종적으로 Memory로 가게 됩니다.
따라서 Memory로 가는데 총 124ns가 필요합니다.
이게 ns라고 사실 그래도 짧다고 생각할 수 있지만, 따지고 보면 레지스터와 메모리는 124배나 차이 난다고 볼 수 있습니다.
경북대를 가는 시간 vs 서울에 가는 시간이라고 볼 수 있습니다. (필자는 자취)
아무튼 이게 한 두 번이면 괜찮은데 계속 반복되다 보면 자연스럽게 성능은 하락하기 마련입니다.
따라서 똑똑한 컴파일러는 가능한 레지스터를 많이 사용할 수 있게 설계를 하여, 레지스터를 효율적으로 쓰게 만들어야 합니다.
따라서 덜 자주 사용되는 변수는 memory로 spill을 해야 하며, 이 과정을 Spilling Register이라고 합니다.
그렇기 때문에 결론적으로 Register Optimization은 매우 중요하다고 볼 수 있습니다.
4.1 Constant or Immediate Operands
많은 프로그램이 상수를 자주 사용합니다.
예를 들면 for문이나 뭐 등등,,,
하지만 1이라는 상수를 메모리에 저장해서 사용할 때마다 레지스터에 넣는다면 매우 비효율적일 겁니다.
따라서 한 번에 더하는 연산을 개발했는데,
추후 뒤에서 나올 I-type이 해당 연산입니다.
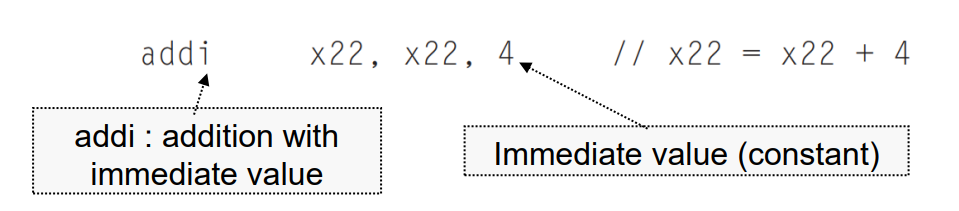
add가 아니라 addi라는 특별한 타입을 만들어서 상수를 바로 더할 수 있게 만들었습니다.
해당 Instruction을 사용함으로써 memory에서 상수를 load 하는 것보다 immediate operand는 매우 빨라졌고, 적은 에너지를 사용합니다.
이러한 개념에서 나온 것이 Hardwired Register입니다.
양수를 음수로 만들 때, 단순히 앞에 -1을 곱하면 되지만, 컴퓨터는 다른 연산이 필요합니다.
따라서 상수 0을 Register x0에 할당함으로써, 이를 보완합니다.
x0은 0으로 고정되어 있기 때문에, lw나 비슷한 명령어를 사용하더라도 무시됩니다.
x1에 있는 값을 음수로 바꾸고 싶다면, sub x1, x0, x1을 사용하면 됩니다.
다음 글에서는 Insturction의 Type에 대해 설명하도록 하겠습니다.
2022.10.01 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Type of Instruction (명령어의 타입)
[컴퓨터 구조] Type of Instruction (명령어의 타입)
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.10.01 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] RISC-V 명령어 작동 과정 (RISC-V Instruction Operation Process) [컴퓨터 구조] RISC-V 명령어 작동..
hi-guten-tag.tistory.com
감사합니다.
지적 환영합니다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Procedure call, jal, jalr (프로시저 콜을 위한 명령어들) (2) | 2022.10.21 |
|---|---|
| [컴퓨터 구조] Decision Instruction (4) | 2022.10.21 |
| [컴퓨터 구조] Type of Instruction (명령어의 타입) (2) | 2022.10.01 |
| [컴퓨터 구조] Assembly Language (컴퓨터의 언어 - 어셈블리어) (0) | 2022.09.24 |
| [컴퓨터 구조] Introduction to Computer Architecture (컴퓨터 구조의 소개) (0) | 2022.09.23 |