논문
https://arxiv.org/abs/1409.4842
Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The
arxiv.org
0. Abstract
- 본 논문에서는 Inception 모듈을 제안합니다.
- 해당 구조의 특징은 컴퓨팅 자원의 효율성을 향상한 것입니다.
- 컴퓨팅 자원은 유지한채 네트워크의 깊이와 넓이를 증가시켰습니다.
- 해당 구조는 Hebbian principle 원리에 기초하여 설계했다고 나와있습니다.
- Hebbian principle은 두 개의 뉴런이 서로 반복적으로 서로를 점화한다면, 상호 연결성이 커진다는 의미이다. 반대도 성립한다.
- 또한 Multi-scale의 직관 프로세싱에도 기초하였다.
1. Introduction
- 최근에는 강력한 하드웨어, 방대한 데이터셋과 큰 모델이 아닌, 새로운 아이디어와 알고리즘이 네트워크 구조를 향상했다고 합니다.
- GoogLeNet은 좋은 성능을 보였는데, 이것은 위 처럼 큰 모델이 아닌, 깊은 구조와 클래식한 컴퓨터 비전의 시너지 덕분입니다.
- 다른 주목할 요인은 모바일, 임베딩 컴퓨팅에서 중요성을 얻었다는 것입니다. 작은 메모리, 파워에서 좋은 성능을 얻었다고 합니다.
- 해당 논문에서는 deep이라는 단어가 두 가지 의미로 사용되었는데, 첫 번째는 Inception module의 구조를 새로운 레벨에서 조직한 것이고, 두 번째는 직관적으로 네트워크 깊이를 향상했다는 의미입니다.
2. Related Work
- 유행하는 설계 방법은 층의 깊이, 층의 크기를 증가시키고, overfitting을 막기 위해 dropout을 사용하는 방식이다.
- network in network는 강력한 표현 능력을 가진다.
- convolution 층을 적용할 때, 1 * 1 convolution layer를 추가해서 봐야 한다. 이것은 CNN 파이프라인이 쉽게 통합할 수 있도록 도와준다.
- 해당 논문에서는 1 * 1 convolution이 두 가지 목적을 가지는데, 계산 bottlenect을 없애기 위해 차원을 감소시키는 것인데, 이것은 깊이를 증가시키고, 또한 네트워크의 넓이도 증가시킨다.
- 또한 R-CNN에서는 low-level의 신호(color, superpixel 등)를 활용하고, CNN을 사용하여 분류하는 것입니다.
- 논문에서는 R-CNN의 구조를 비슷하게 도입하여, multi-box를 강화시켰다고 합니다. 다양한 관점에서 이미지를 보고, 이를 통합하여 더 나은 분류를 하기 위한 것이라고 합니다.
- 즉 논문에서는 1 * 1 convolution을 적극적으로 사용하였고, multi-box를 사용하여 여러 관점에서 이미지를 살펴봤다는 것이 주요 특징입니다.
3. Motivation and High Level Considerations
- 딥러닝 성능을 향상시키는 가장 쉬운 방법은 깊이를 증가시키는 것입니다.
- 이것은 깊이 뿐만 아니라, 넓이를 넓히는 것도 포함합니다.
- 넓이는 각 층의 유닛 개수를 의미한다.
- 하지만 해당 방법은 두 가지 단점을 가지고 있다.
- 일반적으로 큰 모델은 많은 파라미터를 가지고 있는데, 이것은 데이터가 한정적일 때 네트워크가 overfitting이 될 수 있다는 것이다.
- 또 다른 단점은 네트워크 사이즈가 커질수록 컴퓨팅 자원의 사용량이 급격히 증가한다는 것이다.
- 따라서 해당 논문에서는 무차별적으로 사이즈를 증가시키지 않고, 효율적인 컴퓨팅 자원의 분산을 사용한다.
- 위의 두 가지 문제를 해결하기 위해서 Fully Connected를 Sparsely connected architecture로 옮기는 것이다.
- 주요 결과는 데이터 셋의 확률 분포가 크고 매우 희박한 심층 신경망에 의해 표현된다면, 마지막 층의 활성화의 상관 통계를 분석하고 상관 출력이 높은 뉴런을 클러스터링함으로써 최적의 네트워크 토폴로지를 계층별로 구성할 수 있다는 것입니다.
- 즉 위에서 언급한 Hebbian Principle에 따라 클러스터링 된 뉴런들이 서로를 자극함으로써 서로 강화된다는 의미입니다.
- 단점은 불균일한 희소 데이터 구조에 대한 계산이 매우 비효율적입니다.
- 이는 dense한 행렬 곱셈을 사용함으로써 격차는 더욱 확대됩니다.
- 현재 비전 학습은 대부분은 컨볼루션을 활용하기 때문에 공간 영역에서 희소성을 활용합니다.
- 그러나 Convolution은 이전 계층의 패치에 대한 밀도 높은 연결의 모음으로 구현됩니다.
- 따라서 논문에서는 dense 행렬 연산을 활용함으로써 희소성을 확보하고자 합니다.
- Convolution의 희소한 행렬을 상대적으로 dense 한 하위 매트릭스로 클러스터링 한다는 의미.

- 위 그림처럼 상관 관계가 높은 뉴런들을 클러스터링 한다는 뜻임.
4. Architectural Details
- Inception 모듈의 메인 아이디어는 최적의 local 희소 구조가 어떻게 dense 한 구성 요소를 커버되고, 근사화될 수 있는 지를 발견하는 것이다.
- 즉, 최적의 local 구성 요소를 찾고 이를 공간적으로 반복하면 된다는 것이다.
- Sparse 매트릭스를 클러스터링 하여 상대적으로 Dense 한 Submatrix를 만든다는 것이다.
- 결론적으로 1 * 1, 3 * 3, 5 * 5 필터 사이즈를 조합함으로써, 여러 관점에서 이미지를 보고, 이를 합침으로써 Dense 한 Submatrix를 만든다.
- 이때 3 * 3, 5 * 5 필터를 적용하기 전에 1 * 1을 사용하여 dimentional reduction을 합니다.
- 낮은 차원의 임베딩이라도 상대적으로 큰 이미지 패치에 대해 많은 정보를 가지고 있을 수 있다. 하지만 임베딩은 조밀하고, 압축된 형태로 정보를 표현하며, 압축된 정보는 모델링하기가 힘들다는 것이 단점이다.
- 따라서 저자는 표현을 대부분의 장소에서 희소하게 유지하고, 신호가 한꺼번에 합쳐져야 할 때에만 신호를 압축하려 합니다.
- 따라서 1 * 1으로 차원 축소를 적용하고, 표현을 희소하게 유지하며, 최종적으로 신호가 합쳐져야 할 때 신호를 압축합니다.
- 아마 압축은 3 * 3, 5 * 5인 것 같고, 1 * 1을 사용하여 차원을 감소시키면 이전 정보가 희소하게 퍼지므로 이를 이용한 것 같습니다.
- 또한 상위 계층으로 갈수록 5 * 5 필터는 많은 파라미터를 가지는데, 1 * 1 필터를 먼저 적용하여 차원을 감소함으로써 계산 복잡도를 줄인다.

- 최종 Inception 구조는 위와 같다.
- 효율적인 메모리 사용을 위해 낮은 층은 기본적인 CNN 모델을 사용하고, 상위 층에서 Inception module을 사용하는 것이 좋다고 한다.
- 위의 특징을 가지는 Inception module을 사용하면 두 가지 효과가 있다.
- 연산량을 걱정하지 않고, 각 단계에서 유닛 수를 증가시킬 수 있다. 이는 차원 축소를 통해 다음 층의 입력 차원 수를 조절할 수 있기 때문이다.
- 시각 정보가 다양한 관점, Scale로 처리할 수 있고, 다음 층은 동시에 서로 다른 층에서 특징을 추출할 수 있다. 1 * 1, 3 * 3, 5 * 5 Convolution 연산을 통해 다양한 특징을 추출할 수 있다.
5. GoogLeNet

- GoogLeNet의 구조는 위의 표와 같다.
- 해당 모델의 구조를 조금 더 자세히 살펴보자면 크게 4가지가 된다.
- 첫 번째는 Convolution Part이다.
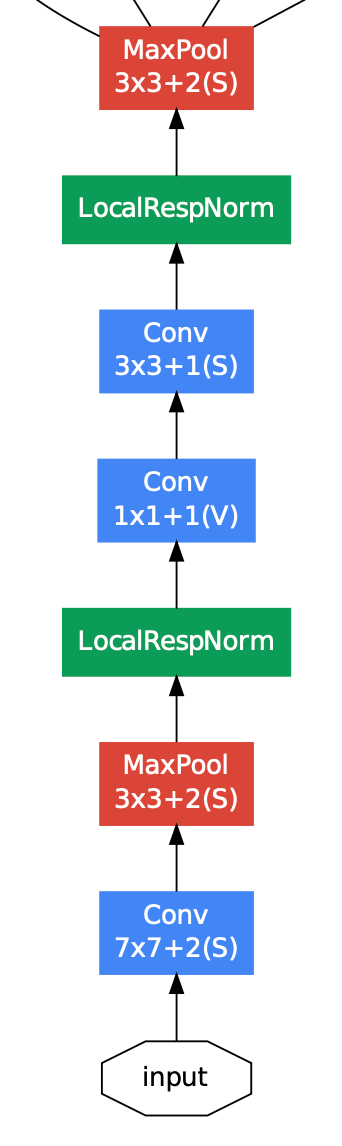
- 해당 부분은 Inception Module에 들어가기 전에 Convolution 연산을 수행한다.
- 표에서 inception(3a)에 들어가기 전의 층이 해당 Part이다.
- 두 번째는 Inception Module이다.
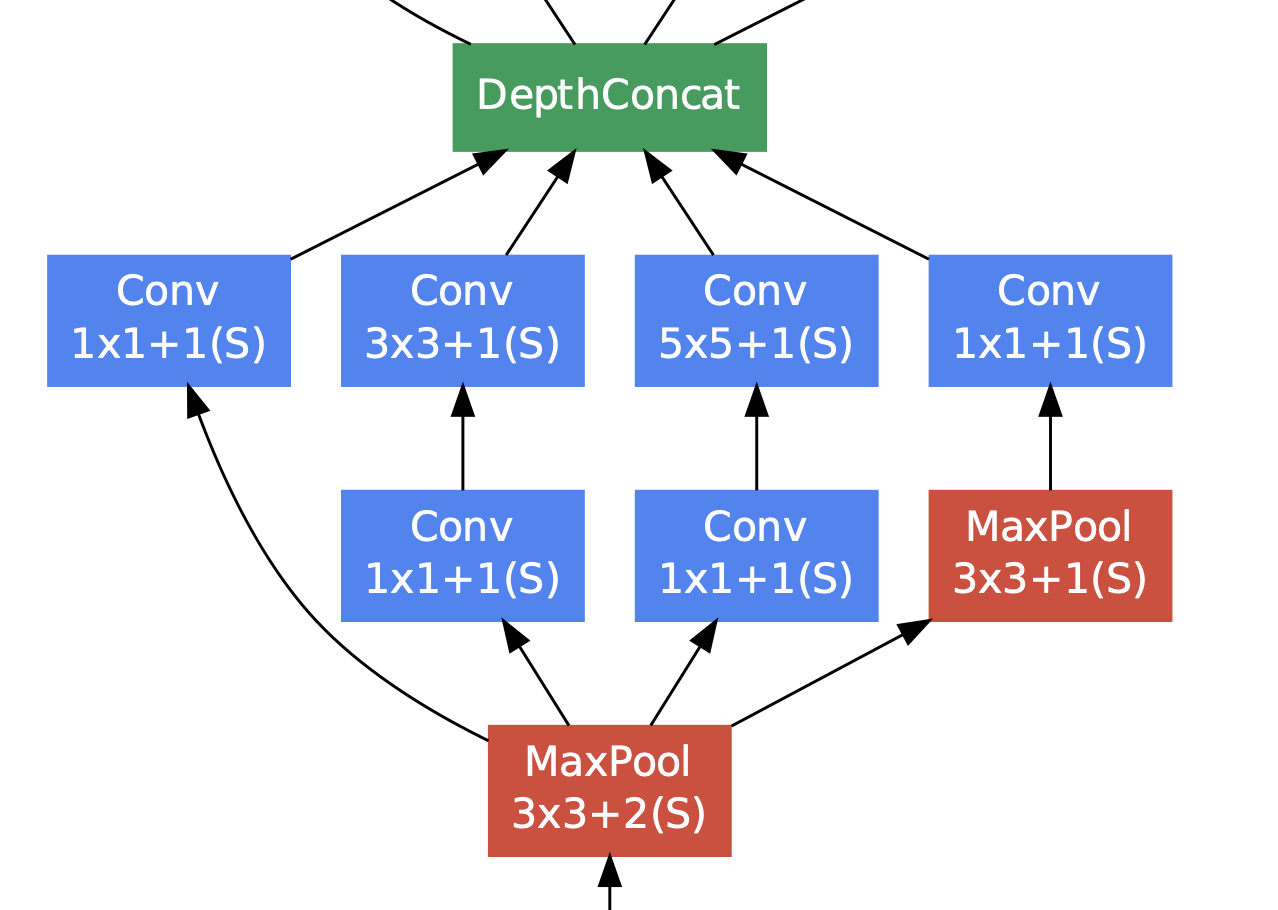
- 위에서 서술한 Inception 연산 과정을 거친 후, DepthConcat를 통해 각기 다른 연산을 합친다.
- 이 과정은 위의 표에서 모든 inception에 적용된다.
- 세 번째는 Auxiliary Classifier이다.
- Auxiliary Classifier은 기울기가 하위 계층으로 갈수록 소실되는 문제점이 있는데, 이를 중간에 보조 분류기를 넣음으로써 기울기를 강화함으로써 해결한다.
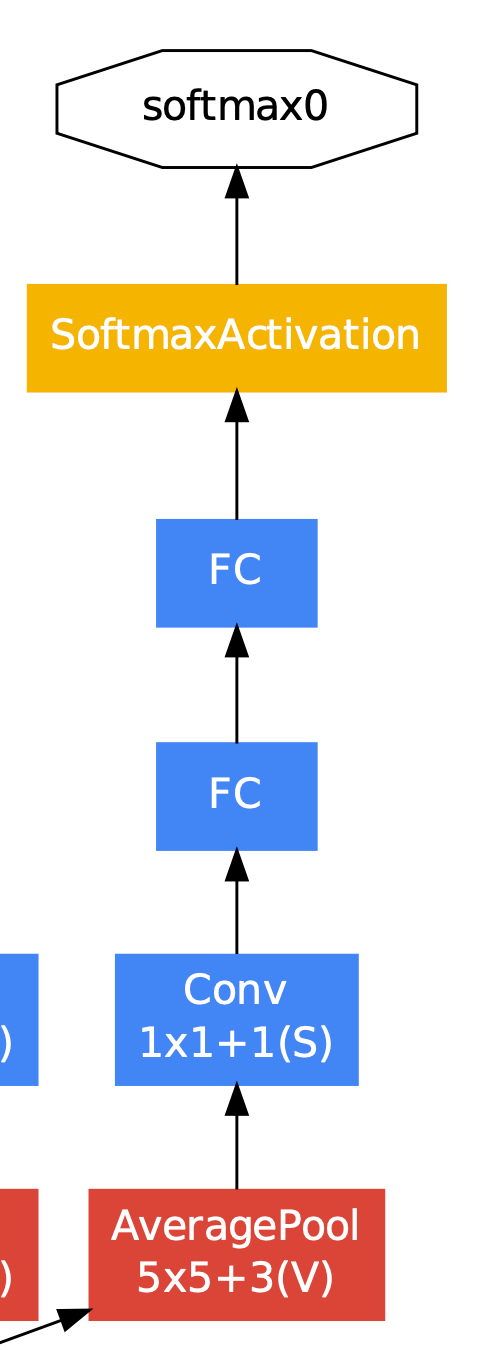
- 해당 보조 분류기는 inception(4a)의 결과와 inception(4d)의 결과에 적용한다.
- 따라서 중간의 결과를 이용하여 보조 분류를 수행한다.
- 마지막은 최종 결정 층이다.
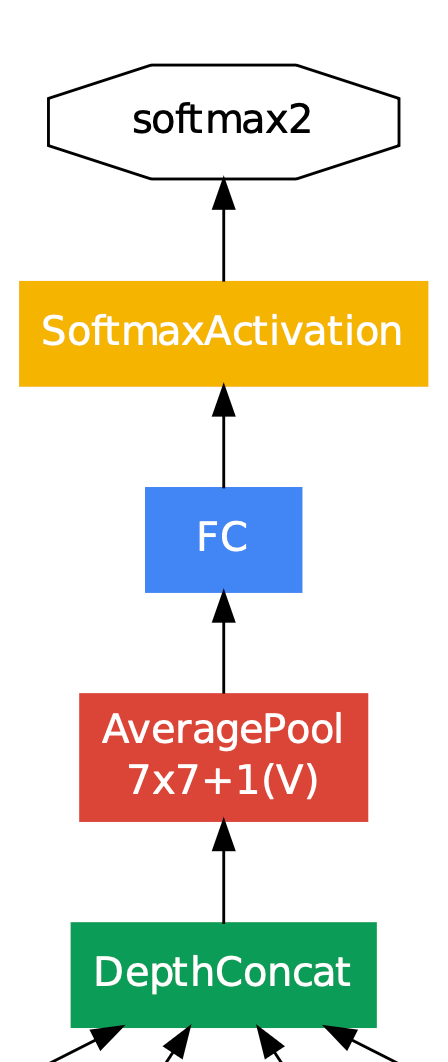
- 위의 표에서 inception(5b) 과정이 끝났을 때, 최종 결과를 출력한다.
6. Training Methodology
- 생략
9. Conclusions
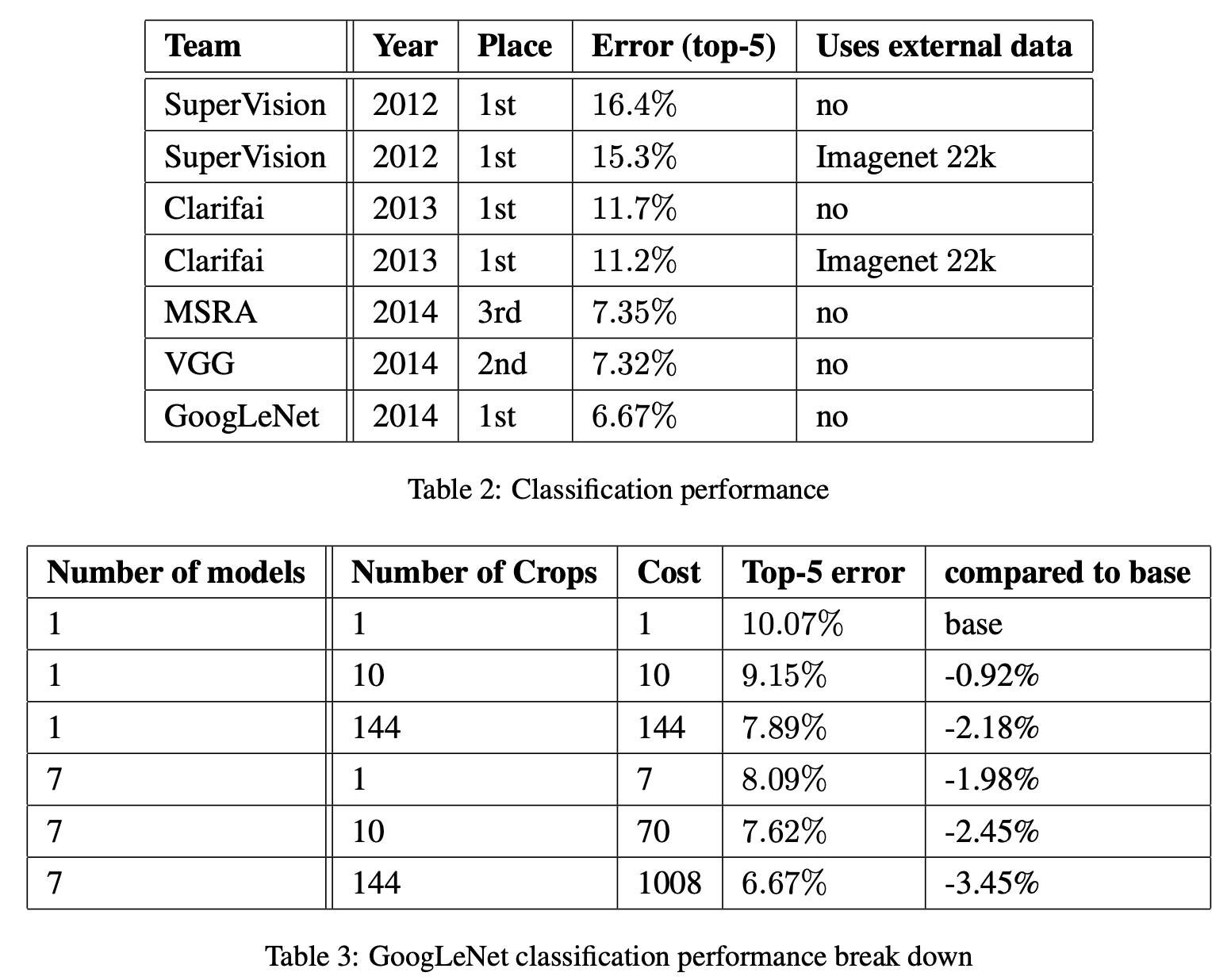
- 결과가 매우 좋다. 최종 제출때는 앙상블 모델을 사용하여 제출한 것으로 알려져있다.
- Number of Crops는 이미지의 높이나 너비를 [256, 288, 320, 352] 사이즈로 resize 한 후에, 왼쪽, 중간, 오른쪽 정사각형을 자른다.
- 이후 좌측 상단, 우측 상단, 중간, 좌측 하단, 우측 하단, [224 * 224] 리사이즈를 통해 6개의 이미지를 추출했다.
- 이를 horizontal flip을 통해 거기서 또 2개의 이미지를 추출했다.
- 따라서 하나의 이미지에서 4 * 3 * 6 * 2 = 144개의 이미지를 추출할 수 있다.
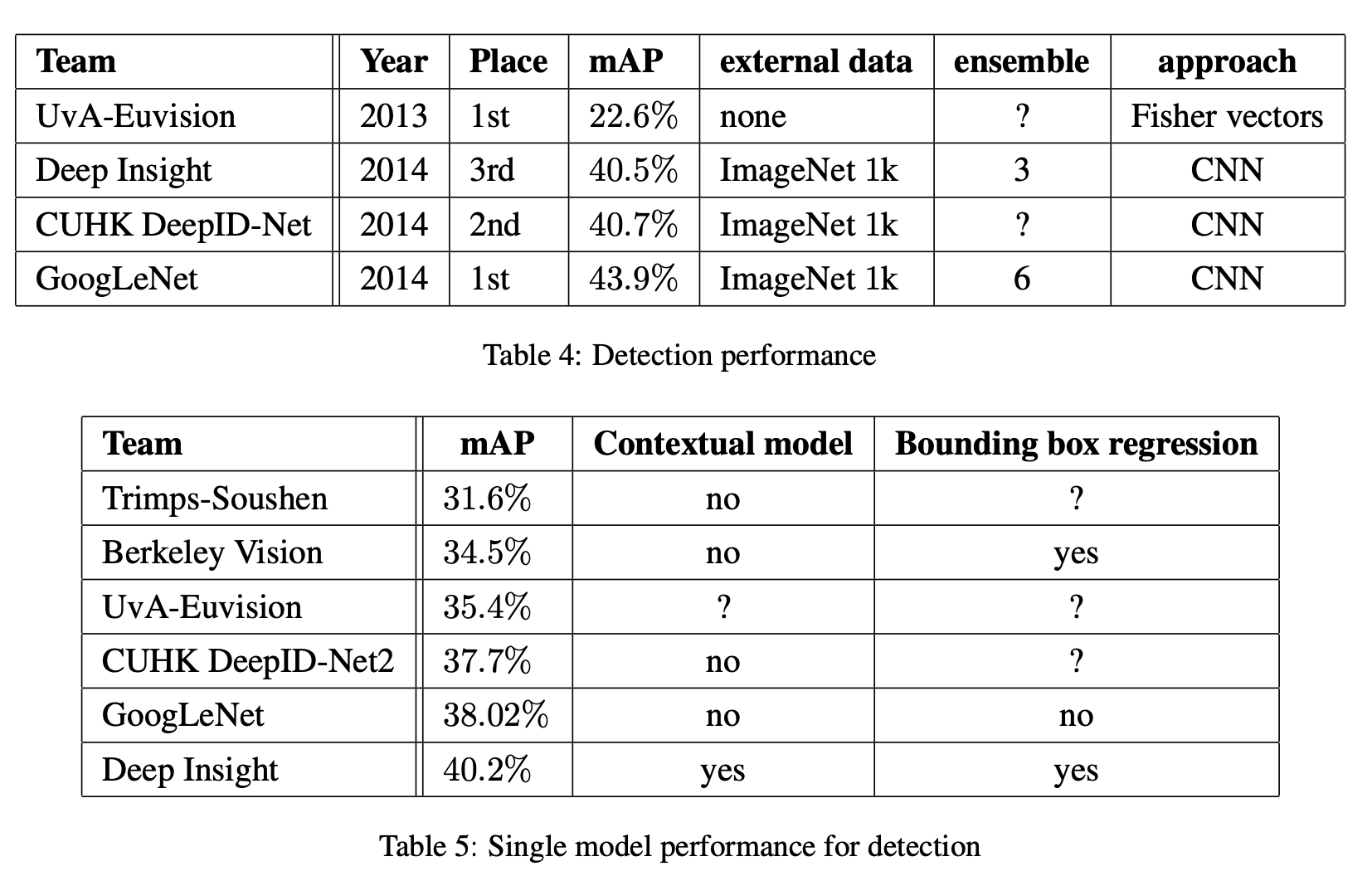
- 다른 Task에도 성능이 뛰어남을 볼 수 있다.
- 최적의 희소 구조를 상대적으로 쉬운 dense 블록으로 근사화 함으로써, 성능을 향상시켰다.
- 얕고, 얇은 네트워크와 비교하여 약간의 연산만 더하고, 높은 성능을 얻을 수 있다.
- 비슷한 깊이와 넓이를 가지는 다른 매우 무거운 네트워크를 통해 비슷한 퀄리티를 얻을 수 있을거라 예상됨에도 불구하고, 저자는 희소한 아키텍쳐를 움직이는 것이 일반적으로 실현 가능하고 매우 유용한 아이디어라고 한다.
마무리
개인적으로 매우 뛰어나다고 생각하는 논문 중 하나이다.
특히 필터를 여러 종류로 쪼개어 사용하고, 보조 분류기를 사용하는 아이디어가 멋있었다.
다만 희소한 구조를 클러스터링하여 밀집도 있게 만든다는 부분이 개인적으로 이해가 잘 가지 않았다.
문장 자체는 이해가 가지만, 어떤 부분이 희소하다는 것인지...?
마지막으로 해당 논문에서 1 * 1 convolution의 사용으로 채널 수를 줄였는데, 이것이 channel reduction의 최초라고 알고 있다.
왜 1 * 1를 사용하게 되었는지 알 수 있어서 좋았다.