1. Image Sementic Segmentation
이미지에 의미가 있는 부분을 세분화하는 작업입니다.

중요한 특징 중 하나로는 output이 크기가 같은 image라는 것이 특징입니다.
2015년에 CVPR이라는 곳에 나온 모델을 보면,

input과 output이 사이즈가 같은 이미지기 때문에 Dense Layer을 없앴습니다.
요즘은 영상이 output이면 Dense Layer을 없애고, Fully Conv Layer을 넣는 경우가 많다고 합니다.
의료분야에서 대표적인 Model은 U-Net입니다.
보시면 처음에 Conv Layer에서 나온 Feature Map을 두 개의 방향으로 보내는 것을 볼 수 있습니다.
아래 방향으로 가면서 중요한 정보들만 추출하고, 다시 upscailing하는 과정에서 이전에 있던 feature map을 더합니다.
이런 이유는 작은 해상도에서 Upscailig하면서 어쩔 수 없이 데이터 손실이 생기고, 큰 사이즈의 feature map을 더함으로써 디테일을 넣어줍니다.
이렇게 함으로써 Output Detail이 좋아집니다.
Output Layer의 값이 Dense Layer이 아닌 Conv Layer입니다.
2. Image Super-Resolution
Super-Resolution (SR)은 초해상화로써 해상도를 높이는 작업입니다.
우리가 사진을 확대하면 화면이 깨지죠? 즉 해상도가 엄청 낮아집니다
왜 그럴까요? 사진을 확대하면 픽셀이 세세하게 안 되어 있어서 어쩔 수 없이 깨지는 현상(계단 현상)이 나타나게 됩니다.
이러한 깨짐을 딥러닝을 통해 Sub-Pixel을 채우는 것이 Super-Resolution입니다.
대표적인 모델로는 ESPCN이 있습니다.
이 모델은 input의 사이즈를 줄이지 않고, 여러 개의 feature map을 추출합니다.
input size가 4 * 4이고, 원하는 SR size가 16 * 16이라고 가정하겠습니다.
이때 SR image에서 좌표 (1,1) ~ (4, 4)까지 모두 기존의 input size의 (1, 1)에서 나온 픽셀입니다.
따라서 최종 단계에서 feature map 16개를 대상으로 (1, 1)에 있는 픽셀을 추출하고, 최종 output의 (1, 1) ~ (4, 4)에 넣는 방식이 ESPCN의 방식입니다.
사실 SR의 엄청난 장점은 데이터의 Label이 따로 필요 없다는 점입니다.
그냥 사진 가져와서 사이즈 4배 줄여버리면 됩니다.
그러면 줄인 사이즈의 이미지가 Train Set이 되는 것이고, 원본 사진이 Label이 됩니다.
따라서 Image Data 때문에 허덕일 일이 없습니다.
SR에는 다양한 모델이 있습니다.
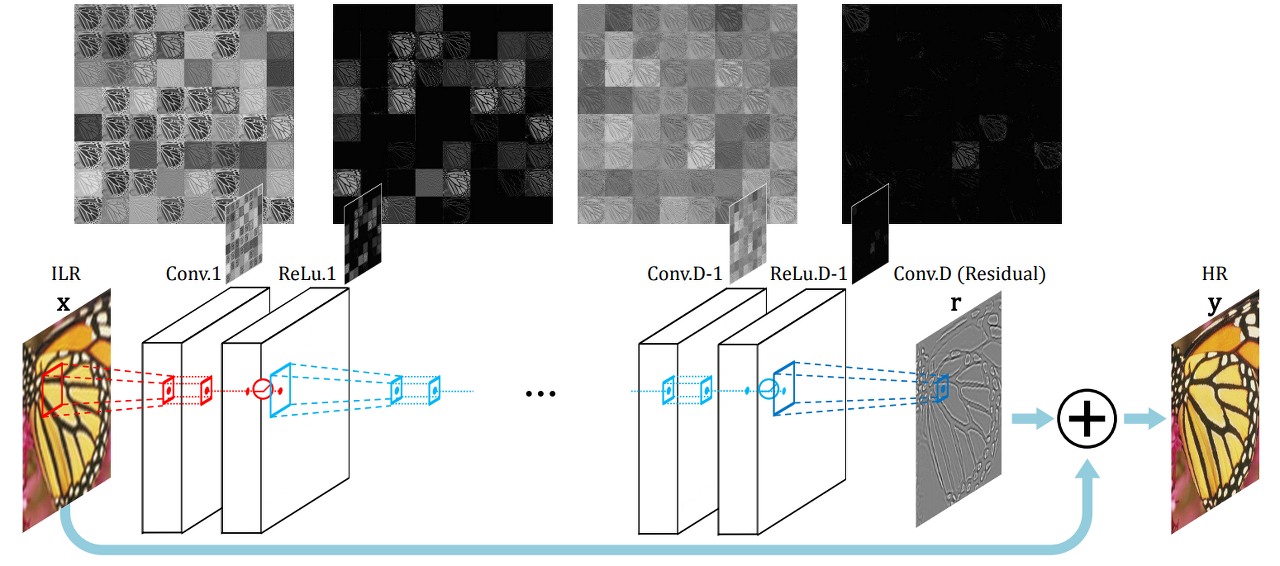
아래의 모델은 VDSR이라는 모델입니다.
또한 SRGAN도 있습니다.

해당 이미지를 볼 때 dB는 SRGAN이 SRResNet보다 낮은데, 뭔가 이미지는 SRGAN이 더 뚜렷하지 않나요?
dB가 높으면 높을수록 원본과 비슷한데, 아무리 봐도 SRGAN이 더 뚜렷합니다.
여기서 가장 중요한 점은 GAN이라는 점입니다.
GAN은 Discriminator을 속이는 것이 목적이기 때문에 '그럴듯한' 이미지를 '생성'하는 것이 목적입니다.
원본을 복원하는 것과는 거리가 멉니다.
이는 곧 무조건적으로 GAN이 좋은 것이 아니라는 것을 의미하며, 그럴듯한 이미지를 생성하는 것과 원본을 복원하는 것은 거리가 멀다는 것을 얘기합니다.
즉 SRGAN은 분별망을 속이기 위해 뚜렷한 이미지를 '생성'한 것이지 원본을 '복원'한 것이 아닙니다.
스스로 학습이 가능합니다. 즉 원본 데이터를 가져와서 1/2, 1/4를 줄이면 그게 학습 세트이고, 원 사이즈가 라벨이 됩니다.
지도 학습이라고 볼 수 있습니다.
3. Image Generation / Translation
이미지 생성은 넘어가고, Translation에 대해 설명하겠습니다.
Translation은 특정 Image를 다른 도메인으로 변환하는 것을 의미합니다.

왼쪽은 말인데 오른쪽은 얼룩말입니다.
이처럼 이미지를 다른 도메인으로 바꾸는 것이 Image Translation입니다.
이때 중요한 것은 Style Transfer이 중요합니다.
즉, Content는 유지하되, Style만 바꾸는 것이 중요합니다.
말의 형상, 그 자체는 그대로 유지해야 합니다.
이때는 3개의 손실 함수를 정의합니다.
- Style Loss
- 스타일은 제대로 변경했는가?
- Content Loss
- 아주 새로운 걸 만들면 안 되고, 기존의 콘텐츠는 살려야 함
- Total Variation Loss
이때 Loss 함수는 기존의 MSE, MAE 같은 게 아니라서 따로 정의해줘야 합니다.
Loss를 기준으로 계산하는 게 정답이 있는 게 아닌가? 싶겠지만, 스타일, 콘텐츠를 수식 통해 계산한 값이 있고, 딥러닝 학습 이후와 현재와 비교를 하기 때문에 비지도 학습에 가깝습니다.