1. Common NLP Tasks (Mixed tasks (NLP + Computer Vision))
일반적인 자연어 처리와 컴퓨터 비전을 합한 작업으로는
- Text-Image search (retrieval)
- 텍스트가 왔을 때 이미지를 보여주거나, 이미지를 보여주면 텍스트를 매칭 시켜줌
- 이는 이미 존재한 것을 매칭 시키는 것
- Image/video captioning
- 새로운 이미지에 자막 등 텍스트를 달아줌
- Etc..
이 있습니다.
이는 곧 이미지나 비디오를 해석해서 사람이 이해할 수 있는 언어로 표현하는 것입니다.
이때 중요한 두 가지 문제가 있습니다.
- 영상을 머신이 이해하는 것
- 그런 이해를 Natural Language로 표현하는 것
애초에 영상을 머신에게 이해시키는 것도 어려운데, 그런 이해를 NL로 표현하는 것도 어렵습니다.
두 개를 합친 문제는 더더욱 어렵습니다..
2. Image Captioning
일반적으로 이미지에 캡션을 다는 것은 정답이 없습니다.

첫 번째 사진을 보면 대략적으로 잘 표현했다는 것을 알 수 있습니다.
근데 과연 이게 정답일까요?
누구는 그냥 단순히 '야구'라고만 할 수 있습니다.
두 번째 사진 또한 누군가는 그냥 '하늘이 맑다' 정도로만 표현할 수 있습니다.
이는 정답이 없다는 것을 의미합니다. 공감은 할 수 있어도...
아무튼 전통적인 이미지 캡셔닝 과정은 다음과 같습니다.
- Image -> CNN -> RNN -> generating captions
우선 CNN으로 영상을 이해하고, 압축된 정보를 RNN을 보냅니다.
이때 함축적인 정보를 받아서, RNN이 그것을 출력합니다.
이때 주의점이 RNN은 Sequence의 길이를 자유롭게 할 수 있지만, 아직은 CNN은 그 정도 수준은 아닙니다.
이미지가 오면 모델에 맞는 사이즈로 변환해줘야 합니다.
또한 RNN을 학습시키기 전에 Text Encoding, Vectorization을 해줌으로써 효과적인 학습을 할 수 있습니다.
여기서 가장 중요한 점은 다음과 같습니다.
일반적으로 이미지 - 캡션이 이루어져 있는 pair은 흔하지 않습니다.
이는 곧 데이터의 부족을 의미하고, 향후 OverFitting이 일어날 가능성을 나타냅니다.
따라서 Data Augmentation을 통해 데이터를 조금 증대시킵니다.
회전, 위치 변환, 명암 조절 등을 통해서 영상의 다양성을 증가시킵니다.
하지만 그렇다 하더라도 텍스트 (캡션)은 변하지 않기 때문에 상관없습니다.
영상의 다양성이 증가한다는 것은 모델에게 조금 회전하거나 명암이 조금 어두워진 것으로 텍스트가 바뀌지 않는다는 것을 알려줍니다.
2.1 Model
Image captioning architecture은 총 세 가지 모델로 이루어져 있습니다.
- CNN
- 이미지의 특징을 추출하기 위해 사용
- Transformer Encoder
- 추출된 이미지의 특징을 Decoder에게 넘겨주기 위해 새로운 표현을 생성해서 넘겨준다.
- 즉 이미지의 특징을 인코딩해서 넘겨줌. Latent Space
- Transformer Decoder
- 인코딩된 데이터와 텍스트 데이터를 받아서 Caption을 생성한다.
3. Text-Image Search
텍스트 이미지 검색을 위해 Dual Encoder이라는 특이한 모델을 사용합니다.
이 모델은 두 개의 encoder 모델로 이루어져 있고, 이 모델들은 이미지를 자연어와 매칭 하기 위해 사용됩니다.
CLIP(Contrastive Language-Image Pre-training)이라는 모델이 있습니다.
3.1 CLIP
일반적인 모델이 CNN -> RNN -> Generation인 반면, CLIP은 어마어마한 영상과 텍스트를 각각 encoding을 합니다.
이후 수많은 값을 중에서 관련이 깊은 걸 matching 시키고, 학습합니다. 즉, 비슷해 보이는 것을 모아놓는 것입니다.
이후 이걸 바탕으로 특정 텍스트나, 특정 이미지가 들어왔을 때 동일하게 인코딩해서 문장을 생성합니다.
장점은 img-text pair가 필요 없어서 많은 데이터를 바탕으로 학습할 수 있다는 것이 장점입니다.
이렇게 많은 그림과 많은 텍스트를 바탕으로 학습합니다.
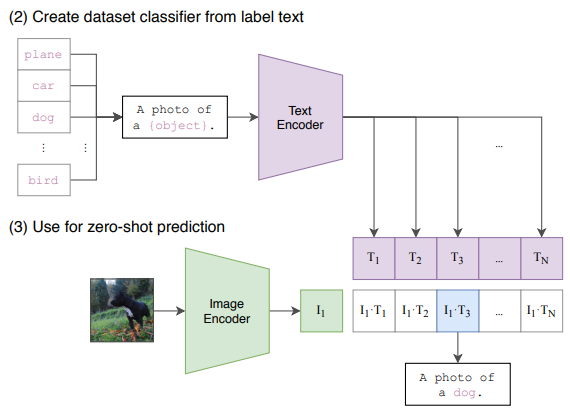
이후 이미지가 주어졌을 때 학습된 이미지 인코더로 이미지 특징을 추출하고, 모든 class label (e.g., 개, 고양이, 바나나 등)을 텍스트 인코더에 통과시켜 텍스트 특징을 추출합니다.
N개의 텍스트 특징들 중 이미지 특징과 가장 높은 상관관계를 가지는 텍스트를 입력 이미지의 물체 분류 결과로 선택하여 출력합니다.
(출처 : https://inforience.net/2021/02/09/clip_visual-model_pre_training/)
(CLIP) 텍스트 정보를 이용한 Visual Model Pre-training
클릭 >> Hello, world !! (from ShadowEgo) 이번 포스트에서는 OpenAI 에서 최근 발표한 CLIP 모델[1]을 소개한다. 이미지, 오디오 등과 같은 데이터의 차원(dimension)을 줄이면서도 보다 의미있는 형태로 변환하
inforience.net
즉. Search for images using natural language queries는 다음과 같은 과정을 거칩니다.
- Generate embeddings for the images by feeding them into the vision encoder
- Feed the natural query to the text encoder to generate a query enbedding
- Compute the similarity between the query embedding and the image enbedding in the index to retrieve the indices of the top matches
- Look up the paths of the top matching images to display them
감사합니다.
지적 환영합니다.